
Responsible AI Security Framework: Building Trustworthy AI

Your AI is already live. Your security framework for it probably isn't.
Employees are using ChatGPT, Copilot, and browser-based AI tools right now. Sensitive data is moving through systems nobody fully mapped or approved.
Security teams get called in after the model ships , not before. By then, the training data is set, the integrations are live, and the attack surface is wide open. This is not negligence. It is the standard enterprise pattern , and it is creating serious exposure.
The numbers make it impossible to ignore. McKinsey identifies cybersecurity as one of the top three risks of Generative AI adoption. Gartner predicts AI deployment bans for noncompliant organizations by 2027.
65% of customers already feel AI adoption has eroded their trust, per Cisco's 2023 Data Privacy Benchmark. That trust deficit grows every time an AI system leaks data, behaves unpredictably, or operates without oversight. The organizations that fix this first will hold a significant competitive and regulatory advantage.
What most security teams are missing is not effort , it is the right framework. Traditional controls were built for network threats, static code, and known attack signatures. AI threats arrive as natural language, inside conversations, through the model itself.
This guide gives you the complete blueprint , built from the ground up for AI systems. It covers responsible AI governance, the OWASP Top 10 for LLMs, the 6-layer security model, and the LEARN architecture. Every section maps directly to controls your team can implement , not theory.
By the end, you will know exactly where your AI security posture stands. You will know which layers are missing, which threats are unaddressed, and what to build next. And you will see precisely how LangProtect closes each gap , at runtime, in real time.
Good catch on both , the direct answer was functioning like a section summary, which kills the reading flow. And the links were visibly "placed" rather than earned. Here's the corrected version:
What Is an Enterprise AI Security Framework, and Why Do Most Organizations Not Have One?
An enterprise AI security framework is a set of layered controls that governs how AI models are trained, deployed, accessed, and monitored across an organization. It is not a single tool or policy , it is an architecture that covers data, models, infrastructure, employees, access, and compliance simultaneously.
Most organizations don't have one. Not because they don't care about security , but because the way enterprise AI gets built makes security almost impossible to add at the right time.
Here's what typically happens.
An engineering team builds an AI application. They move fast , business pressure demands it. By the time anyone thinks to loop in the security function, the model has already been trained, the application is in internal testing, and in some cases it's already serving real users. Security teams are handed a live system and asked to secure it retrospectively.
This isn't a failure of intent. It's a structural problem with how AI development is sequenced.
According to research published by Trend Micro, three barriers consistently prevent organizations from building proper AI security frameworks before deployment:
- Security teams lack deep familiarity with LLMs, RAG systems, and AI model training, the concepts feel foreign, so security reviews happen at the surface level or not at all
- Business units are under intense pressure to ship AI features fast, secure design principles get treated as obstacles to speed rather than requirements for production readiness
- Security teams don't know which layers need protection, without visibility into AI-specific risk surfaces, it's impossible to know what "done" looks like
The result is a stack of AI systems operating without a framework designed for them.
The Trust and Compliance Problem Is Already Here
The consequences aren't hypothetical anymore.
Cisco's 2023 Data Privacy Benchmark Study found that 65% of customers feel AI adoption by organizations has already eroded their trust. That's not a future risk , it's a present-day business problem. And it stems directly from the absence of transparent, governed AI systems.
On the regulatory side, the pressure is compounding. By 2026, Gartner anticipates that over half of governments globally will mandate responsible AI , enforcing data privacy and ethical AI practices as legal requirements.
The Gartner Market Guide for AI Trust, Risk, and Security Management goes further, predicting that companies without compliant AI governance could face deployment bans from regulators by 2027. That's not a distant warning. Organizations building AI systems today without a security and governance framework are accumulating regulatory exposure they may not be able to unwind.
And McKinsey consistently identifies cybersecurity as one of the top three risks of Generative AI adoption , sitting alongside workforce disruption and intellectual property exposure as the risks executives lose sleep over most.
Why Adding Security Later Doesn't Work for AI
Traditional software has a useful property: you can patch it. You find a vulnerability, you write a fix, you deploy it. The underlying system stays intact.
AI doesn't work this way.
AI models are shaped by data, not just code. If a model was trained on a poisoned dataset , one that introduced backdoors, biases, or manipulated outputs , there is no patch. You would need to retrain the model from scratch on clean data. By the time you discover the problem, the model may have been in production for months, making decisions that affected real users and real business outcomes.
Once a model is live, every interaction is an attack surface. Every prompt a user submits, every document a RAG system retrieves, every tool call an agent makes, all of it is a potential vector for prompt injection, data leakage, or behavioral manipulation. Unlike a web application where you can enumerate endpoints, an LLM's attack surface is conversational and effectively infinite.
Shadow AI compounds everything. Employees don't wait for IT security reviews. They adopt tools that make them faster , and they adopt them immediately. By the time your security team has assessed a new AI tool, employees have been using it for weeks.
LangProtect Guardia typically uncovers 3–5x more AI tools in active use than IT has on record , and most of that usage involves data the security team would not have approved.
The core truth is this: you cannot retrofit a security framework onto an AI system the way you can retrofit a firewall onto a web application. The threat surface is different, the attack vectors are different, and the remediation options are fundamentally more limited once the model is deployed.
That's what makes getting the framework right , before deployment , so critical. And that's what the rest of this guide is built to help you do.
The 7 Responsible AI Principles That Form Your Governance Foundation
Responsible AI governance is the foundation of a defensible AI security posture. Without it, organizations cannot enforce consistent data handling, detect model bias or drift, or prove compliance during a regulatory audit. The seven core principles are: Transparency, Inclusiveness, Factual Integrity, Understanding Limits, Governance, Testing Rigor, and Monitoring.
Most security teams treat AI governance as an ethics or legal concern , not a security one. That's the wrong frame.
Governance principles determine whether your AI systems can be audited, your policies enforced, and your compliance posture defended when a regulator asks hard questions. Without them, your technical controls have no foundation.
Here's what all seven require , and what skipping any one of them actually costs you.

Principle 1: Transparency , Can You Explain What Your AI Is Doing?
If your security team can't explain how an AI system reached a decision, they can't identify when that decision was manipulated, produce evidence for a compliance audit, or detect behavioral drift.
What transparency requires in practice:
- Every AI response is clearly labeled , not presented as human-generated
- AI systems maintain explainability logs documenting the reasoning path behind outputs
- Model capabilities and limitations are documented before deployment , not after an incident
According to the Cisco 2023 Data Privacy Benchmark Study, 65% of customers feel AI adoption has already eroded their trust. Transparency is the primary mechanism for rebuilding it.
Principle 2: Inclusiveness , Biased Data Is a Security Problem
Biased training data produces unpredictable, inconsistent model behavior , and attackers who understand those blind spots can craft inputs designed to exploit them.
What this requires operationally:
- Training datasets audited for representation gaps before model training begins
- Models tested across diverse demographic contexts , not just primary use cases
- Bias detection treated as a pre-launch security control, not a post-launch quality check
Principle 3: Factual Integrity , Hallucination Is Not Just a Quality Problem
When an AI model hallucinates , produces confident but false information , the downstream consequences create real liability. OWASP classifies misinformation as a Top 10 LLM risk specifically because hallucinated outputs that appear credible cause serious organizational harm.
Control requirement: AI systems must use retrieval validation mechanisms , such as RAG with verified source databases , that ground outputs in evidence rather than guesswork.
Principle 4: Understanding Limits , Knowing What Your AI Cannot Do
Every model has a boundary where knowledge ends and guesswork begins. Organizations that don't define those limits create two problems:
- User overreliance, people treat AI outputs as authoritative when they aren't
- Scope creep, AI systems deployed in contexts they were never designed or tested for
Document limitations before deployment. Build technical controls that prevent AI systems from operating outside their defined scope.
Principle 5: Governance , Policies That Are Actually Enforced
AI governance means documented policies, comprehensive records of model behavior, and technical enforcement mechanisms that make those policies real , not just written.
A policy that says "don't paste confidential data into AI tools" is not a control. It's a suggestion.
What real AI governance looks like:
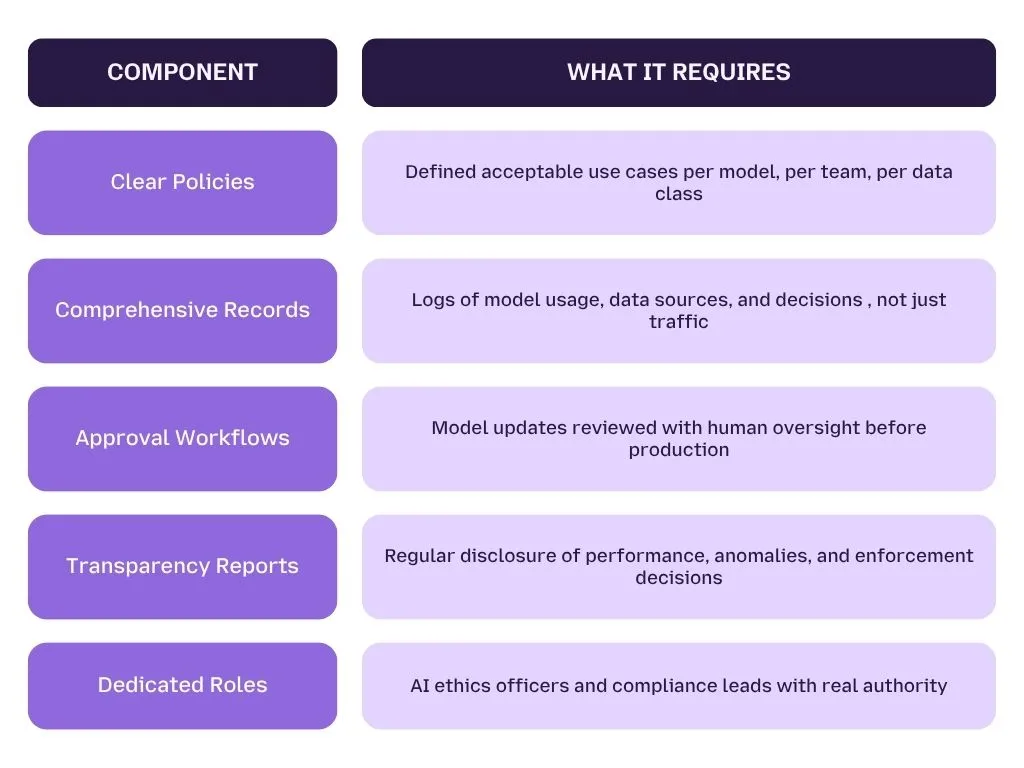
The Gartner Market Guide for AI Trust, Risk, and Security Management warns that by 2027, organizations without compliant AI governance could face deployment bans from regulators. LangProtect enforces these policies at runtime , every prompt, output, and agent action evaluated, logged, and surfaced in audit-ready reports.
Principle 6: Testing Rigor , Pre-Launch and Post-Launch, Without Exception
Most organizations test before launch. Almost none continue testing after it. Both are required.
Pre-launch testing must cover:
- Bias and inaccuracy detection across diverse use cases and demographic groups
- Adversarial testing , prompt injection attempts, jailbreaks, and edge-case inputs
- Red team exercises that simulate real attacker behavior against the model
Post-launch testing must cover:
- Continuous regression testing when models are updated or fine-tuned
- Behavioral drift detection , comparing live outputs against established baselines
- User feedback integration , employees will surface failure modes automated monitoring misses
Pro Tip
Map every category from the OWASP Top 10 for LLM Applications to a specific test case before your next model goes to production. If your pre-launch security review doesn't address all 10, it's incomplete.
Principle 7: Monitoring , Security Doesn't End at Deployment
Continuous AI monitoring means systematically tracking model performance, detecting behavioral anomalies, collecting user feedback, and responding to deviations before they become incidents. A model that passed every pre-launch test can still be manipulated at runtime , monitoring is what catches it.
AI models don't behave identically over time. They shift with new inputs, respond to conversational manipulation, and drift in ways no pre-launch test anticipates.
Continuous monitoring requires:
- Ongoing output quality and consistency checks against established baselines
- Behavioral anomaly alerts when model responses deviate meaningfully
- Structured user feedback channels to capture real-world failure signals
- A defined response process , not just recording monitoring signals, but acting on them
LangProtect's runtime monitoring layer tracks every prompt, output, and enforcement decision , producing behavioral anomaly alerts and compliance-ready audit logs automatically, at scale.
Why All 7 Must Work Together
These principles are not a menu. They are a system. Transparency without Monitoring means you can explain your AI's design but not its live behavior. Testing Rigor without Governance means results nobody acts on. Skip one principle and the others weaken.
Organizations that implement all seven build a posture that regulators can audit, attackers find harder to breach, and compliance teams can defend. The next section shows exactly what those attackers are targeting , and which vulnerabilities your AI applications are most exposed to right now.
The OWASP Top 10 for LLMs, What Your AI Applications Are Actually Vulnerable To
Direct Answer: The OWASP Top 10 for Large Language Model Applications identifies the most critical vulnerabilities in AI systems , assessed by impact, ease of exploitation, and real-world prevalence. These threats include prompt injection, sensitive information disclosure, data poisoning, excessive agency, and improper output handling. None of them can be detected by firewalls, SIEMs, or traditional DLP tools.
Your AI applications have a specific, documented threat taxonomy. Most security teams aren't using it.
The OWASP Top 10 for LLM Applications is the industry-standard framework for understanding where LLM-based systems fail , and how attackers exploit those failures. It was built because AI vulnerabilities don't map to traditional CVEs. They live in conversations, training pipelines, output streams, and agent behaviors that legacy security tools were never designed to inspect.
Below is every relevant risk, translated into plain language, with the control required to address it.
OWASP Top 10 for LLMs, Full Risk and Control Mapping
| OWASP ID | Risk Name | What It Means in Plain Language | LangProtect Control |
|---|---|---|---|
| LLM01 | Prompt Injection | Malicious instructions hidden in user input, documents, or third-party content hijack the model's behavior | Armor , semantic intent detection in under 50ms |
| LLM02 | Sensitive Information Disclosure | The model leaks PII, PHI, API keys, or confidential data in its responses | Guardia , scans outputs before delivery to the user |
| LLM03 | Supply Chain | Vulnerabilities in third-party models, datasets, or plugins compromise the entire application | Pre-deployment vendor audit + runtime integrity monitoring |
| LLM04 | Data & Model Poisoning | Training or fine-tuning data is manipulated to introduce backdoors, biases, or corrupted outputs | Pre-deployment data audit + Armor runtime anomaly detection |
| LLM05 | Improper Output Handling | AI-generated outputs aren't validated before being passed to downstream systems or users | Armor , output filtering and response validation layer |
| LLM06 | Excessive Agency | AI agents take damaging actions , deleting files, sending emails, executing queries , beyond their intended scope | Vector , least-privilege enforcement per agent, per task |
| LLM07 | System Prompt Leakage | System instructions containing sensitive business logic, credentials, or configuration are exposed | Armor , prompt hardening and output filtering |
| LLM08 | Vector & Embedding Weaknesses | RAG systems are exploited to surface unauthorized, poisoned, or manipulated data | Armor , runtime RAG access control and input validation |
| LLM09 | Misinformation | The model generates false, hallucinated, or misleading outputs that appear credible and authoritative | Factual integrity controls + output confidence monitoring |
| LLM10 | Unbounded Consumption | Attackers send resource-intensive queries to exhaust compute, drive up costs, or cause denial of service | Rate limiting and usage governance via LangProtect |
What This Table Tells You
Three patterns stand out when you look at the full OWASP Top 10 for LLMs:
- Most risks happen at runtime, not during training or pre-deployment testing. They emerge from live interactions, real user inputs, and production agent behavior
- Traditional security tools address zero of them, there is no firewall rule for prompt injection, no SIEM signature for excessive agency, no DLP pattern for system prompt leakage
- LLM01 (Prompt Injection) sits at the top for a reason, it is the most exploitable, most prevalent, and hardest to detect of all LLM vulnerabilities
Why Prompt Injection Is the Most Dangerous LLM Vulnerability
Direct Answer: Prompt injection is the highest-priority LLM risk because it requires no code change, no malware, and no network access. A single malicious instruction embedded in a user message or external document can completely redirect what an AI system does , and it looks identical to normal usage from the outside.
Traditional attacks have signatures. Prompt injection does not.
It operates entirely through natural language , which means the same capability that makes LLMs powerful (understanding and following instructions) is exactly what makes them vulnerable. You cannot write a firewall rule for a sentence.
The three conditions that make prompt injection catastrophic:
- The model ingests untrusted content, user input, external documents, web pages, emails
- The model has access to private data, internal databases, customer records, source code
- The model can communicate externally, APIs, file systems, email, third-party services
When all three conditions exist simultaneously, a single malicious prompt can extract sensitive data and exfiltrate it without triggering a single alert in your existing stack. Security researchers call this the "lethal trifecta", and most enterprise AI deployments meet all three criteria by default.
Real-world proof: Within 24 hours of Google releasing its Gemini-powered AI coding tool Antigravity, a security researcher demonstrated that a single malicious code snippet , once marked as trusted , could reprogram the agent's behavior and install a persistent backdoor. The backdoor survived restarts and reinstalls. No infrastructure exploit was used. The failure came entirely from the model's agentic autonomy and its willingness to act on unvetted input.
This is not an isolated edge case. It is a demonstration of what happens when an LLM system operates without runtime enforcement.
LangProtect Armor addresses this specifically , evaluating the semantic intent behind every prompt in under 50ms, not just its surface-level content. It detects adversarial intent even when the attacker uses indirect language, multilingual obfuscation, or "Chameleon's Trap" techniques designed to bypass keyword-based filters.
The 6-Layer AI Security Blueprint, What You Actually Need to Implement
A complete enterprise AI security framework requires six distinct layers of protection: securing training data, securing AI models, securing AI infrastructure, governing employee AI usage, controlling access to AI services, and defending against zero-day exploits at the network level. Each layer addresses a different attack surface , and no single layer is sufficient alone.
Most security frameworks treat AI as one surface to protect. It isn't.
AI systems have six distinct attack surfaces , each requiring a different control set, a different toolset, and a different owner inside your security organization. The framework below, aligned to research from Trend Micro's Security for AI Blueprint, maps each layer to what organizations need to implement , and where gaps most commonly appear.
The 6-Layer AI Security Framework, Overview
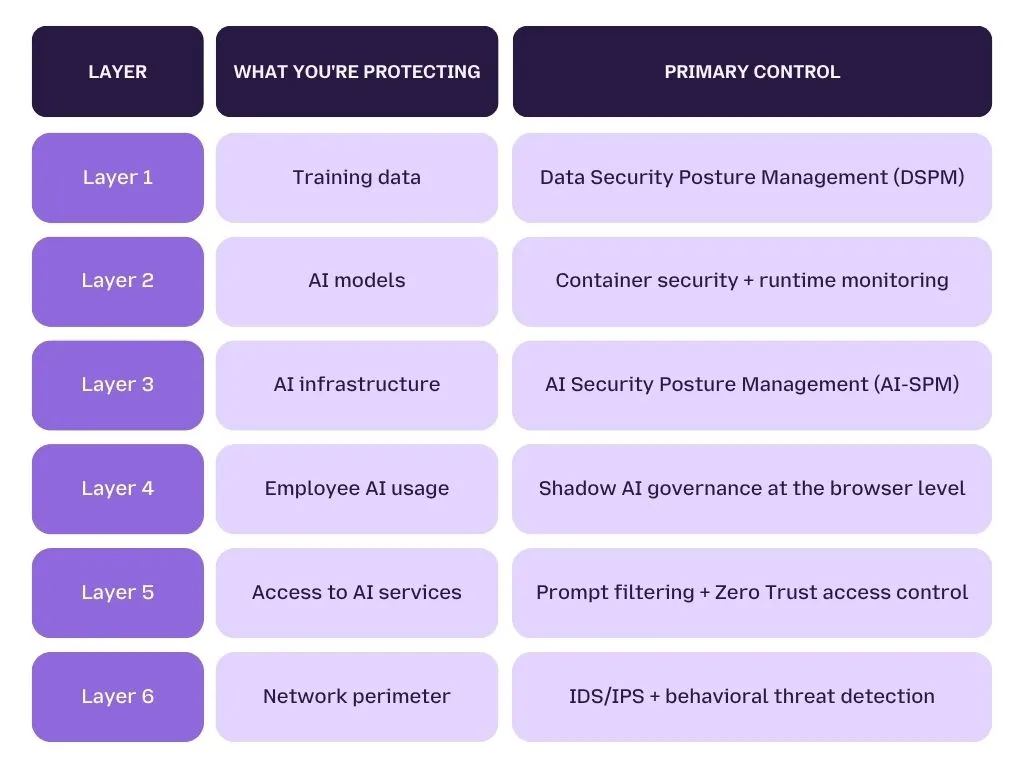
Layer 1 - Secure Your Training Data
What you're protecting: The data that shapes your model's behavior, knowledge, and outputs.
Data is the backbone of every AI system. It determines what the model knows, how it responds, and what biases it carries into production. If this layer is compromised, no downstream security control can fully compensate.
The core problem:
Without proper data classification, sensitive information, PHI, PII, financial records, proprietary business logic , gets fed into AI training pipelines undetected. Once it's in the model, it doesn't stay contained. AI models often memorize training data, which means unclassified personal or confidential information fed in at training time can be extracted later through carefully crafted adversarial prompts.
What Data Security Posture Management (DSPM) does:
- Systematically identifies and categorizes data before it reaches training pipelines
- Enforces access controls and monitoring around AI-specific data flows
- Detects when sensitive data is being included in model training without authorization
- Provides real-time visibility into potential data exfiltration paths
Key risk: If a model has memorized PHI from an unclassified training dataset, an attacker doesn't need to breach your database. They just need to ask the model the right question.
Layer 2 - Secure Your AI Models
What you're protecting: The models themselves, the intellectual property, the behavioral integrity, and the outputs they produce.
AI models are increasingly deployed in containerized environments , Kubernetes clusters, Docker containers, cloud-hosted inference endpoints. These environments are scalable and flexible, but they introduce attack surfaces that traditional application security wasn't built to address.
Why model security matters:
- Intellectual property protection, AI models represent significant R&D investment. A compromised model can have its proprietary architecture reverse-engineered through repeated querying (model extraction)
- Data integrity, manipulated models produce incorrect outputs that look authoritative, leading to faulty decisions at scale
- Regulatory compliance, many industries require that AI models meet specific data protection and integrity standards before deployment
What securing AI models requires:
- Real-time container security monitoring , detecting anomalies in runtime behavior, not just scanning images at build time
- Continuous vulnerability scanning , running before deployment and throughout the model's operational lifecycle
- Network segmentation , isolating containers running AI models from other infrastructure to limit lateral movement in the event of a breach
- Comprehensive logging , enabling forensic reconstruction of model behavior after an incident
Layer 3 - Secure Your AI Infrastructure
What you're protecting: The cloud environments, configurations, and platform services that host and serve your AI systems.
A model can be perfectly designed and still be exposed through a misconfigured cloud environment. This is one of the most common and most overlooked attack surfaces in enterprise AI, because infrastructure security and AI security are typically owned by different teams who don't consistently coordinate.
What AI Security Posture Management (AI-SPM) provides:
- Full infrastructure visibility , understanding every component, configuration, and data flow within your cloud AI environments
- Proactive misconfiguration detection , identifying infrastructure gaps before attackers find them, not after a breach
- Compliance monitoring , continuously checking whether AI infrastructure meets GDPR, HIPAA, PCI-DSS, and EU AI Act requirements
- Vulnerability management, scanning AI application software stacks for known vulnerabilities and providing remediation guidance
The critical distinction: AI-SPM is not a replacement for general cloud security posture management , it's an additional layer that understands AI-specific infrastructure patterns, data flows, and risk categories that general CSPM tools don't model.
Layer 4 - Secure Employee AI Usage (Shadow AI)
What you're protecting: Every AI interaction your employees initiate , including the ones your IT team doesn't know about.
This is the layer most organizations underestimate , and the one with the most immediate real-world exposure.
Employees don't adopt shadow AI tools to create security incidents. They adopt them because those tools make them meaningfully faster at their jobs. A clinician summarizing patient notes in ChatGPT. A developer pasting source code into Gemini. A finance analyst uploading a contract into an unauthorized copilot. None of these are malicious acts , but all of them create serious data exposure.
The scale of the problem:
- Employees adopt AI tools 3–5x faster than IT security teams can assess and approve them
- Most enterprises are aware of only 20–30% of the AI tools actively in use across their organization
- Shadow AI usage bypasses SSO, IAM, DLP, and audit logging , creating a class of interactions that is completely invisible to your existing security stack
What governing employee AI usage requires:
- Real-time visibility into every AI tool in use , approved and unapproved
- Prompt and file inspection at the point of submission , before data leaves the browser
- Policy enforcement that applies consistently across all tools, not just sanctioned ones
- User guidance that redirects employees to safe alternatives rather than simply blocking them
LangProtect Guardia operates at the browser level , intercepting sensitive prompts and file uploads before they reach any AI tool, whether it's an approved enterprise copilot or an unauthorized public LLM. It detects PII, PHI, API keys, and proprietary data in real time and gives employees the guidance to correct risky behavior without disrupting their workflow.
For healthcare organizations specifically, where PHI exposure through employee AI tools carries HIPAA liability, this layer is foundational , see our detailed breakdown in Securing AI Agents in Healthcare.
Layer 5 - Secure Access to AI Services (Prompt Filtering + Zero Trust)
What you're protecting: Every point where users, employees, or systems interact with AI models , including through APIs, browser sessions, and enterprise integrations.
Controlling access to AI services is not just about authentication. It's about governing what happens inside authenticated sessions , what prompts are submitted, what outputs are returned, and what actions are triggered as a result.
The risks at this layer:
- Unsanctioned usage , employees accessing AI services through personal accounts or unofficial channels
- Data exfiltration , sensitive data submitted through AI interfaces without organizational oversight
- Prompt injection via AI services , malicious inputs that manipulate model behavior through standard API channels
- Unsecured GenAI responses , model outputs that violate compliance requirements or contain harmful content delivered directly to users
What securing AI access requires:
- Central visibility of all AI services in use , including shadow tools operating outside approved channels
- Prompt filtering that detects and blocks malicious or policy-violating inputs before they reach the model
- Rate limiting to prevent abuse, runaway agent behavior, and cost escalation
- Response filtering to ensure AI outputs are safe and compliant before delivery to users
- Zero Trust access control , verifying user identity, risk level, and context before granting access to any AI resource
LangProtect Armor implements prompt filtering, output validation, and runtime policy enforcement at the application layer , with under 50ms latency. Every request is evaluated, every response is checked, and every enforcement decision is logged.
To understand how prompt-level threats exploit this layer, see our full technical breakdown in What Is Prompt Injection?
Layer 6 - Defend Against Zero-Day Exploits at the Network Level
What you're protecting: The network infrastructure that surrounds your AI systems , against threats that exploit unknown vulnerabilities before patches exist.
Zero-day exploits target vulnerabilities that have no published fix. For AI systems , which process sensitive data at scale and have become high-value targets , these exploits can cause significant damage before any mitigation strategy can be deployed.
Why AI systems are prime zero-day targets:
- The sensitive nature of AI-processed data makes these systems extremely attractive to attackers
- AI applications often rely on complex software stacks with multiple dependency layers , each a potential entry point
- Cloud-hosted AI infrastructure introduces network-level exposure that on-premises security reviews may not fully account for
What defending against zero-day exploits requires:
- Network IDS/IPS , real-time traffic monitoring that identifies suspicious activity and potential exploit attempts as they happen
- Behavioral analysis , establishing baselines of normal network behavior and flagging deviations that indicate zero-day activity
- Virtual patching , automated shielding of known vulnerabilities while permanent patches are prepared and tested
- Threat intelligence integration , continuous feeds of emerging threat data that allow proactive protection before exploits are widely deployed
LangProtect Vector exports agent security telemetry directly to Splunk, Microsoft Sentinel, and Datadog , giving your SOC real-time visibility into AI-specific threats without creating a separate monitoring silo. Every agent action, every blocked request, every anomalous behavior is surfaced in the tools your security team already uses.
The LEARN Architecture - A Named Framework for Securing LLM Applications
Direct Answer: The LEARN Architecture is a five-component security framework for LLM applications that systematically addresses prompt injection, integrity risks, privacy exposure, and hallucination. It stands for Linguistic Shielding, Execution Supervision, Access Control, Robust Prompt Hardening, and Nondisclosure Assurance , and each component maps to a specific, implementable runtime control.
Most security frameworks describe what to protect. LEARN describes how to protect it , at the LLM interaction layer specifically.
Developed by Trend Micro Research and aligned to OWASP Top 10 LLM risk categories, the LEARN Architecture gives security teams a named, structured model they can use to audit, build, and communicate AI application security , without needing to invent their own taxonomy from scratch.
The LEARN Framework, Full Component Breakdown
| Component | What It Protects Against | What It Does in Practice | LangProtect Product |
|---|---|---|---|
| L , Linguistic Shielding | Prompt injection, jailbreaks, harmful inputs | Inspects and filters inputs before they reach the model , blocking adversarial language, indirect injections, and policy-violating content | Armor , semantic injection detection |
| E , Execution Supervision | Excessive agency, unauthorized agent actions | Monitors every action taken by AI agents and models at runtime , detecting and blocking behaviors that fall outside defined operational boundaries | Vector , agent action control |
| A , Access Control | Unauthorized model access, over-permissioned users and agents | Restricts who and what can interact with the model and its data , enforcing least-privilege at the user, role, and agent level | Vector , least-privilege enforcement |
| R , Robust Prompt Hardening | Prompt manipulation, system prompt leakage, output misalignment | Strengthens the prompts and system instructions used with the model , making them resistant to manipulation and ensuring outputs align with intended behavior | Armor , prompt validation layer |
| N , Nondisclosure Assurance | Sensitive information disclosure, PII/PHI leakage, data exfiltration | Prevents the model from returning personal, confidential, or regulated data in its outputs , applying redaction before responses reach users or downstream systems | Guardia + Armor , PII/PHI redaction |
How LEARN Maps to the OWASP Top 10 for LLMs
The LEARN Architecture doesn't exist in isolation , each component directly addresses specific OWASP LLM risk categories:

Why LEARN Works as an Operational Framework
Three things make LEARN practically useful for security teams , not just theoretically sound:
It's auditable. Each component has a clear definition, a measurable outcome, and a specific control that implements it. You can audit whether Linguistic Shielding is in place the same way you'd audit whether a firewall rule is configured.
It's communicable. LEARN gives security leaders a vocabulary for explaining AI application security to non-technical stakeholders , board members, compliance officers, and regulators who need to understand what protections exist without understanding LLM architecture.
It's implementable now. Unlike governance frameworks that require months of policy development, LEARN maps directly to runtime controls that can be deployed into existing AI application stacks , without requiring model changes or application redesigns.
Building AI Security That Scales With Your Organization
Most enterprise AI security conversations start in the wrong place.
They start with the tool , which model to use, which vendor to evaluate, which feature to enable. They treat security as a layer you add on top of an AI system that's already been designed, built, and deployed.
This blueprint argues the opposite: security is not a layer you add to AI. It is a condition your AI systems must meet before they operate.
That distinction matters because of what's now at stake.
The OWASP Top 10 for LLMs documents the attack surface. The 7 responsible AI principles define the governance foundation. The 6-layer security blueprint maps the controls you need at every level , from training data to network perimeter. And the LEARN Architecture gives you a named, auditable framework to build against and communicate upward.
None of these are theoretical constructs. They are the product of real incidents, real regulatory pressure, and real organizational failure , documented by McKinsey, Gartner, Cisco, OWASP, and the security researchers who study LLM vulnerabilities full-time.
What a Complete AI Security Framework Looks Like, In One View
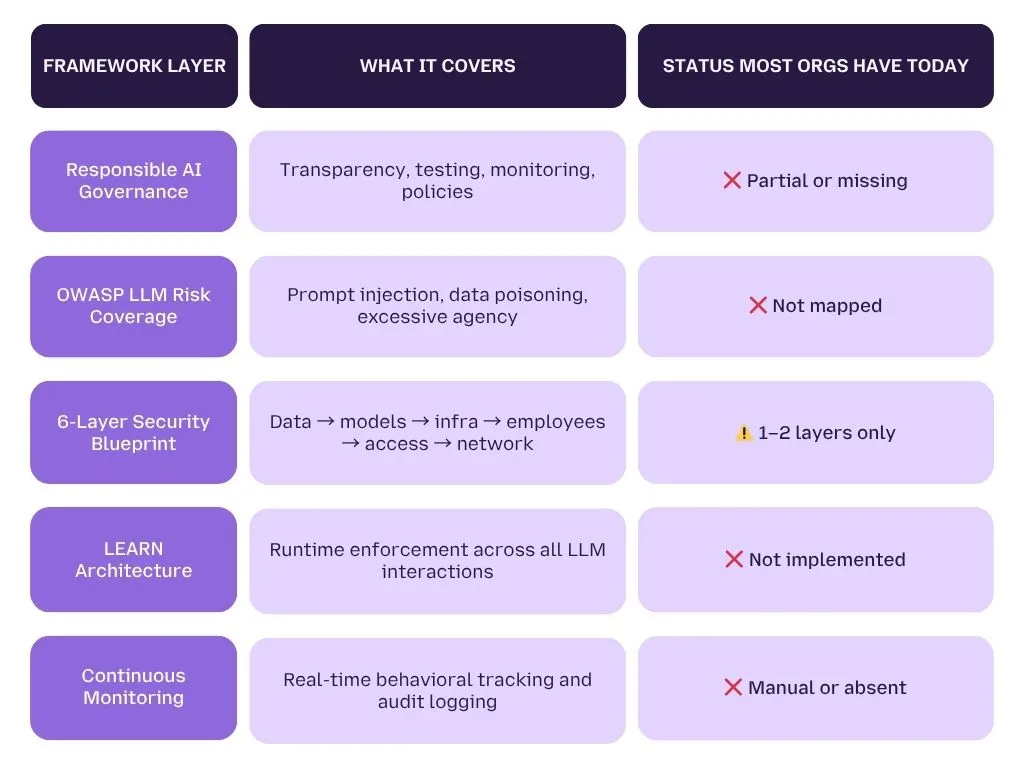
If your organization has gaps across more than two rows of that table , and most do , you are operating AI systems with an incomplete security posture. The question is not whether that posture will be tested. It's whether you'll know when it is.
Where LangProtect Fits
LangProtect was built to close the gaps that every framework above identifies , but that no traditional security tool was designed to fill.
- Guardia governs employee AI usage at the browser level , covering Layer 4 of the security blueprint and the N (Nondisclosure Assurance) component of LEARN
- Armor enforces runtime security for homegrown LLM applications , covering Layers 5, and the L, R, and N components of LEARN , with under 50ms latency
- Vector secures AI agents with least-privilege enforcement and full action logging , covering Layer 6 and the E and A components of LEARN
Together, they cover every component of the LEARN Architecture and every runtime layer of the 6-layer blueprint , without requiring changes to your models, your application logic, or your existing security infrastructure.
The Last Word on AI Security Frameworks
A framework is only as useful as the controls that implement it.
You can have the most comprehensive AI governance policy ever written. You can map every OWASP LLM risk to a mitigation strategy. You can define responsible AI principles and socialize them across every team.
None of it stops a prompt injection attack at 2am. None of it catches an employee pasting patient records into a public chatbot. None of it blocks an AI agent from accessing a database it was never supposed to touch.
What stops those things is enforcement , at runtime, at the prompt level, at the moment the threat actually occurs.
That is what a complete enterprise AI security framework delivers. And that is what LangProtect is built to provide.
Ready to Build Your AI Security Framework?
See how LangProtect maps to the OWASP Top 10 for LLMs, the LEARN Architecture, and your specific AI deployment, in a single 30-minute session.
No lengthy onboarding. No disruption to your current stack. Just a clear, honest picture of where your AI security posture stands and what it takes to close the gaps.
Frequently Asked Questions
Q: What is an enterprise AI security framework?
An enterprise AI security framework is a structured, multi-layer system of controls that governs how AI models are trained, deployed, accessed, and monitored across an organization. It covers data protection, model security, infrastructure governance, employee AI usage, access control, and compliance monitoring. Without one, organizations have no systematic way to detect or respond to AI-specific threats like prompt injection, data poisoning, or excessive agent agency.
Q: What is the OWASP Top 10 for LLM applications?
The OWASP Top 10 for LLM Applications is the industry-standard threat taxonomy for AI systems , covering the most critical vulnerabilities including prompt injection, sensitive information disclosure, data and model poisoning, excessive agency, and system prompt leakage. It is assessed by real-world impact, ease of exploitation, and prevalence. Security teams use it to audit AI applications against documented attack vectors that traditional tools like SIEMs and DLP systems cannot detect.
Q: What is the LEARN Architecture for AI security?
LEARN is a five-component security framework for LLM applications developed by Trend Micro Research. It stands for Linguistic Shielding, Execution Supervision, Access Control, Robust Prompt Hardening, and Nondisclosure Assurance. Each component maps to a specific runtime control and directly addresses OWASP LLM risk categories. It gives security teams an auditable, communicable framework for protecting LLM applications at the interaction layer , not just at the perimeter.
Q: What are the 7 principles of responsible AI governance?
The seven core responsible AI principles are Transparency, Inclusiveness, Factual Integrity, Understanding Limits, Governance, Testing Rigor, and Monitoring. They form the governance foundation that makes technical AI security controls enforceable and auditable. Without them, organizations cannot consistently enforce data handling policies, detect model drift, or produce the compliance evidence that regulators now require under frameworks like the EU AI Act and HIPAA.
Q: Why can't traditional security tools protect AI systems?
Traditional tools , firewalls, SIEMs, and DLP systems , were built to detect known threat signatures in network traffic and structured data. AI threats operate differently. Prompt injection arrives as natural language. Data leakage happens inside model outputs. Excessive agent agency looks like normal API activity. None of these generate alerts in a conventional security stack because they were never designed to inspect what happens inside an AI conversation , only where traffic goes, not what it contains.