
AI DLP: How to Stop Sensitive Data Exposure in AI Tools

Enterprise data security programs have historically been designed around a predictable threat model of sensitive information moving across identifiable channels such as email attachments, removable storage, or cloud synchronization services.
Data Loss Prevention tools were built around that architecture, and within it, they have performed reliably. The problem is that the architecture no longer reflects how enterprise data actually moves.
Generative AI tools have introduced a transfer channel that existing DLP controls were not designed to observe.
Separately, browsing telemetry analysis shows that employees make an average of 46 pastes per day into browser-based applications, with GenAI tools accounting for 32% of all corporate-to-personal data movement making it the single largest exfiltration channel in the enterprise today.
What makes this particularly difficult to govern is that the mechanism of typing or pasting into a browser prompt generates no file transfer event, no email record, and no network pattern that a conventional DLP policy is built to detect.
The gap, in other words, is not a misconfiguration. It is structural. Traditional DLP was designed to inspect data as a static object at a known transfer point. The AI prompt channel operates differently: data enters as natural language, moves through a browser interaction, and reaches an external model without passing through any of the control surfaces a perimeter-focused security stack is positioned to monitor.
The average enterprise now runs 54 generative AI applications, and research indicates that nearly 40% of sensitive data interactions with AI tools involve information employees should not be sharing not out of malicious intent, but because the workflows have evolved faster than the controls.
This article defines what AI DLP is as a technical category, examines precisely where traditional DLP's architectural assumptions break down at the AI channel, and provides a structured evaluation framework for security teams assessing solutions so that investment decisions are grounded in the specifics of how these controls work, not in vendor positioning.
Not sure what your AI tools are currently exposing?
Find out with a free LangProtect Guardia prompt audit, see exactly what is leaving your environment before it becomes a reportable event.
Good. Writing the full section now with Definition callout, H3/H4 hierarchy, bullets, and two visual elements (a data type list block + a paradigm comparison table).
What Is AI DLP (AI Data Loss Prevention)?
AI DLP AI Data Loss Prevention is a purpose-built data-protection capability designed to inspect, classify, and enforce policy on sensitive information flowing through AI tool interactions including natural language prompts, file uploads to AI platforms, API calls between enterprise systems and AI models, and AI-generated outputs returned to the user. It is distinct from traditional DLP in both the enforcement layer and detection method.
What Types of Sensitive Data Flow Into AI Tools?
Sensitive data does not enter AI tools in a single, predictable form. Across enterprise environments, the data types that most frequently appear in AI interactions include the following:
- Personally Identifiable Information (PII): names, addresses, national identification numbers, contact records
- Protected Health Information (PHI): patient records, diagnoses, medication histories, medical record numbers
- Financial data: account numbers, transaction records, earnings statements, credit card data
- Intellectual property: proprietary source code, internal product specifications, research and development documentation
- Legal and contractual content: draft agreements, litigation strategy, regulatory correspondence
- Authentication credentials: API keys, access tokens, service account passwords embedded in code snippets
A 2025 survey of employees at large enterprises found that 57% had submitted sensitive company data into publicly available AI platforms, with the categories above representing the primary data types involved. The majority of these submissions occurred through copy-paste interactions the precise channel that traditional DLP architectures were not built to observe.
What Does AI DLP Actually Monitor?
AI DLP operates across three distinct interaction surfaces that collectively constitute the AI data exposure perimeter:
Why AI DLP Is Not Traditional DLP With an AI Feature Added
The distinction between the two is not cosmetic. It reflects a fundamental difference in how each treats sensitive data conceptually and where each applies enforcement.
Traditional DLP: Data as a Static Object at a Known Channel
Traditional DLP was designed around the premise that sensitive data exists as an identifiable object, a file, a record, a structured field, and that data loss occurs when that object crosses a known transfer boundary.
Policy enforcement is applied at those boundaries: the email gateway intercepts attachments, the endpoint agent monitors USB activity, the network proxy inspects cloud sync traffic.
Detection relies primarily on pattern matching against known data formats, which works reliably when the data is structured and the channel is predictable.
AI DLP: Data as a Live, Unstructured Flow Into an External Model
The AI prompt channel violates both assumptions. Sensitive data arrives as natural language unstructured, context-dependent, and indistinguishable from non-sensitive text without semantic understanding.
It crosses no identifiable transfer boundary; it moves as a standard HTTPS POST request to a third-party API endpoint, indistinguishable in form from thousands of other browser interactions.
Research based on enterprise browsing telemetry confirms that copy-paste into GenAI tools has become the primary blind spot for data leakage, with 77% of employees pasting data into GenAI prompts the majority from unmanaged personal accounts that exist entirely outside enterprise policy enforcement.
AI DLP addresses this by moving enforcement upstream to the prompt itself, applying semantic entity classification rather than pattern matching, and operating at the browser layer where the interaction is composed before it leaves the device.
Why Can't Traditional DLP See AI Data Leaks?
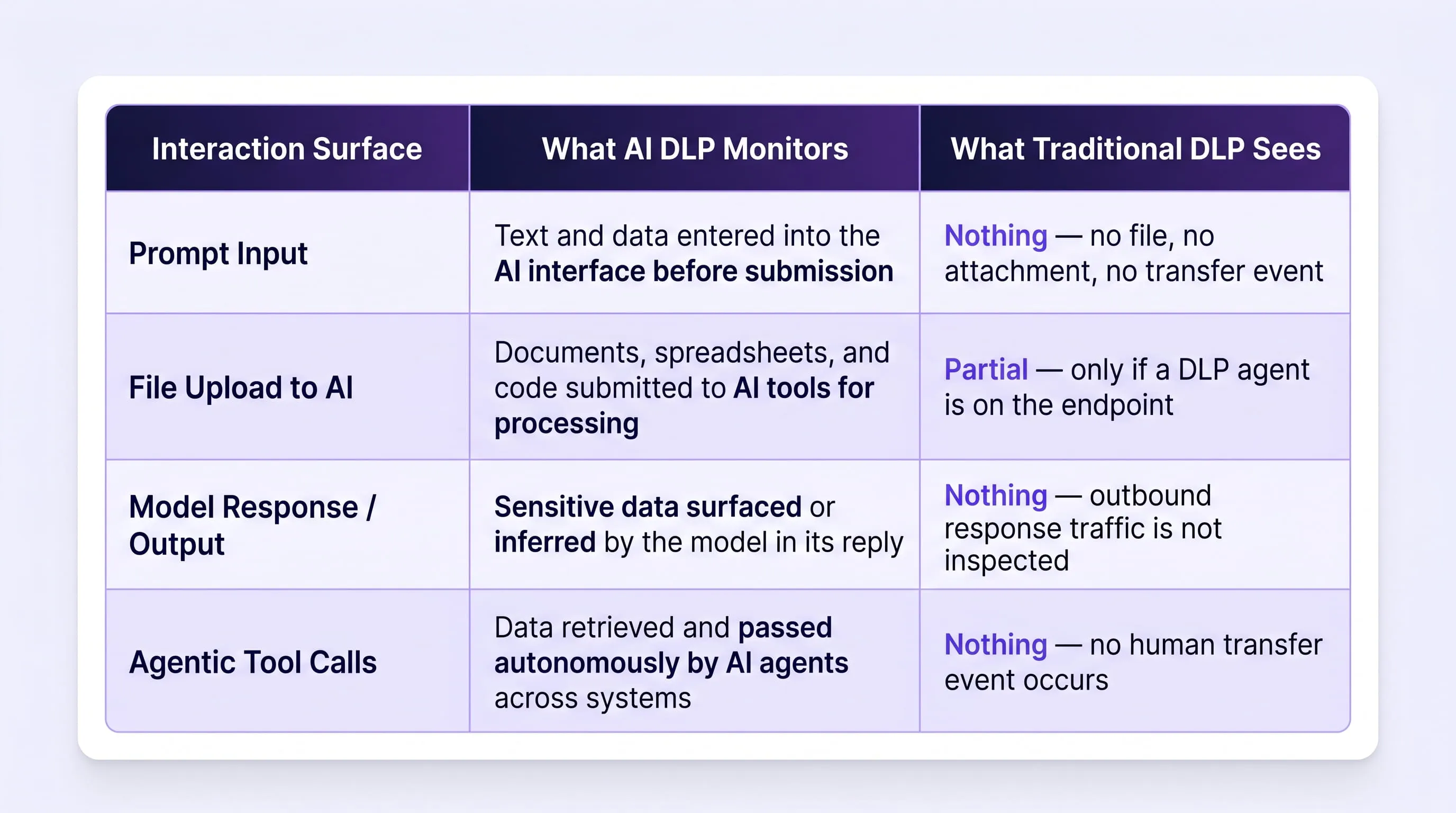
Traditional DLP inspects fixed transfer points, email attachments, USB transfers, cloud synchronization events using pattern matching against known data formats. When an employee enters sensitive data into a browser-based AI prompt, there is no file, no attachment, and no network event of the kind that a perimeter-focused DLP architecture was designed to intercept. The data moves as unstructured text inside a standard HTTPS request, and from the perspective of every control in a conventional DLP stack, nothing unusual has occurred.
How Traditional DLP Was Designed to Work
To understand the gap precisely, it is necessary to start with the architecture traditional DLP was built around. The foundational assumption is that sensitive data exists as an identifiable object a file, a structured record, a classified document and that data loss events occur when that object crosses a defined transfer boundary. Each DLP control sits at one of those boundaries and applies policy at the point of crossing.
This architecture has been operationally effective for the threat model it was designed to address. The problem is that AI tool interactions do not map onto any of the surfaces in the table above. There is no file, no email, and data does not move to a cloud sync destination that a CASB policy recognizes as a controlled transfer event. It moves as a browser prompt.
Difference between AI Interactions and Traditional DLP Coverage
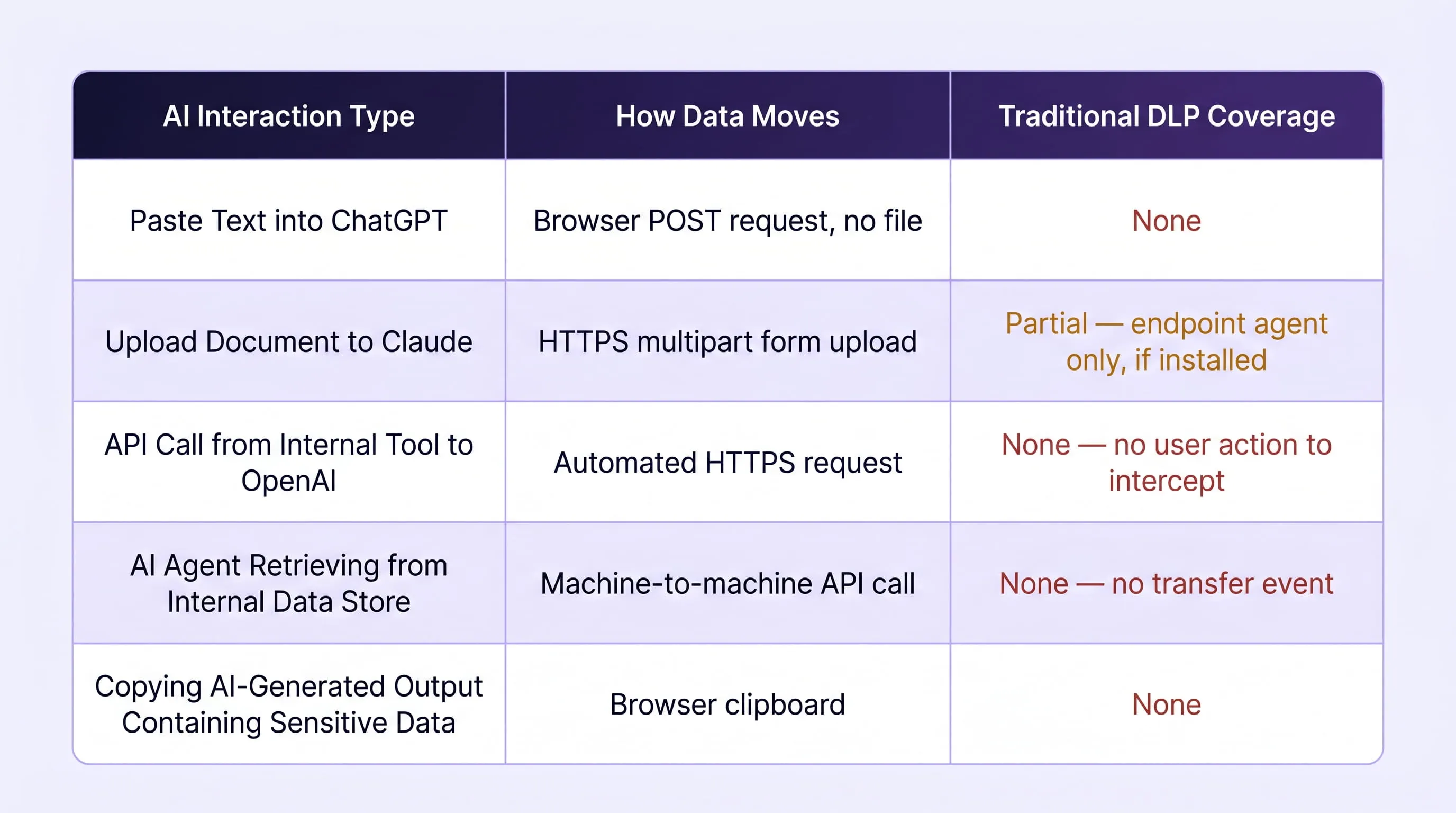
The Four Blind Spots in Legacy DLP
The coverage gap in the table above is not the result of poor configuration or insufficient DLP rules. It reflects four structural blind spots that are architectural in nature and cannot be closed by tuning an existing DLP deployment.
Blind Spot 1: Copy-Paste Leaves No Transfer Event
When an employee copies data from an internal system and pastes it into an AI tool, no file is created, no attachment is generated, and no outbound network pattern matches a DLP policy rule. The data exits the enterprise as unstructured text inside the body of a standard browser request.
Industry telemetry shows that employees average multiple pastes into AI tools per day, with the majority of that activity occurring through personal accounts where enterprise controls have zero reach, even when network-level inspection is deployed. Traditional DLP was never instructed to observe this interaction.
Blind Spot 2: Pattern Matching Has No Semantic Context
Legacy DLP detection relies on regular expressions and fingerprinting against known data patterns a Social Security Number format, a credit card number structure, and a classified document hash.
This approach fails in the context of natural language prompts because sensitive data in a prompt does not present itself as a structured field. A name alongside a number could be an innocuous reference or a customer record. A paragraph of text could contain proprietary strategy or a publicly available summary.
Traditional tools rely on file scanning and pattern matching, which cannot detect sensitive data pasted into browser-based AI prompts because the detection mechanism requires known structure that natural language does not provide.
Without semantic understanding of what the data means in context, pattern matching produces both false positives and, more critically, false negatives at scale.
Blind Spot 3: The Browser Layer Is Invisible
Enterprise DLP architectures divide enforcement between two surfaces: the network layer, which observes traffic between the device and external destinations, and the endpoint layer, which monitors local file activity.
Neither surface has visibility into the content of a browser prompt. The network proxy sees that traffic is going to chat.openai.com , a destination that may be permitted under policy. The endpoint agent sees that the browser process is active.
Security teams believe they have significant DLP coverage, but they are actually lacking visibility into where data moves most frequently today: directly in the browser, where employees interact with AI tools, copy data between applications, and input information into web forms and prompts. The prompt content itself, the actual sensitive data is invisible to both layers.
Blind Spot 4: AI Agents Move Data Machine-to-Machine
The most significant emerging gap in traditional DLP coverage is autonomous AI agent activity.
An AI agent operating within an enterprise environment may query an internal knowledge base, retrieve records from a CRM, synthesize outputs across multiple data sources, and pass results to an external model or downstream system all without any human transfer event that a perimeter DLP tool is positioned to intercept.
Legacy DLP logs file access. It does not track which internal knowledge an agent retrieved to answer a question, what embeddings it queried, or what external tools it authenticated against in the process. As agentic AI adoption accelerates, this blind spot represents the fastest-growing unmanaged exposure surface in enterprise data security.
The Blind Spot in Enterprise Data Protection
The blind spots described above are not a criticism of traditional DLP programs or the security teams that operate them. These tools were built for a specific threat model and they continue to serve that purpose effectively.
The AI channel simply represents a new data surface that did not exist when enterprise DLP architectures were designed and it requires a purpose-built control to address it.
For a full breakdown of the specific data leakage vectors in AI environments and the regulatory obligations each one triggers, see AI data leakage vectors and the compliance requirements each one activates.
What a Real AI Data Leak Looks Like in the Logs
The following is a representative example of how a sensitive data submission to an AI tool appears from the perspective of a conventional security stack.
// Outbound request captured at network proxy
Timestamp: 2026-06-10T09:41:17Z
Method: POST
Destination: https://chat.openai.com/backend-api/conversation
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64)
TLS: Encrypted (TLS 1.3)
Payload (partial):
{
"model": "gpt-4o",
"messages": [{
"role": "user",
"content": "Refactor this for performance:\n\n
[287 lines of proprietary source code containing
internal API endpoints, database connection strings,
authentication tokens, and unreleased product architecture]"
}]
}
// Security stack response
DLP Alert: NONE
SIEM Alert: NONE
Network Block: NONE
Policy Violation: NONE
Audit Log Entry: NONE
From the perspective of every control in a conventional security stack, this interaction does not exist. The network proxy records a successful TLS connection to a permitted destination. The endpoint agent records normal browser activity.
No DLP rule fires because no DLP rule is watching this surface. The Samsung incident of 2023 in which engineers pasted proprietary semiconductor source code into ChatGPT, where it became part of the model's training data is the documented example of this exact failure pattern. Traditional DLP tools observed the interaction and recorded no violation.
This is the gap that AI DLP is built to close, not by replacing the controls above, but by adding enforcement at the one surface none of them observe: the prompt layer, before the data reaches the model.
See What Your DLP Is Missing Right Now
LangProtect's prompt-layer enforcement gives your security team complete visibility into what sensitive data is entering your AI tools and intercepts it before it reaches the model.
How Does Traditional DLP Compare to AI DLP?
Traditional DLP and AI DLP are not competing implementations of the same control they are distinct architectures built around fundamentally different assumptions about how sensitive data moves and where enforcement must occur. Traditional DLP governs data as it crosses identifiable transfer boundaries using structural pattern recognition. AI DLP governs data as it flows through unstructured AI interactions using semantic classification at the browser and prompt layer. Understanding the distinction is essential to evaluating where each belongs in an enterprise security stack, and why deploying one does not substitute for the other.
Traditional DLP was architected around the premise that sensitive data loss occurs when a known data object , a file, a structured record, a classified document, crosses a defined transfer boundary such as an email gateway, a USB port, or a cloud synchronization event.
Enforcement follows logically from that premise: position controls at those boundaries, apply pattern matching against known data formats, and block or alert when a match is detected.
The AI prompt channel violates both the premise and the enforcement mechanism simultaneously. When an employee enters sensitive information into a generative AI tool, the data moves as natural language within a standard browser request unstructured, context-dependent, and indistinguishable from non-sensitive text without semantic understanding of the content.
Legacy DLP has no concept of an AI prompt, was never designed to inspect the content of a conversation with an AI assistant, and even well-tuned legacy policies miss data moving through AI interfaces entirely.
DLP incidents related to generative AI tools more than doubled in early 2025, now representing 14% of all enterprise data security incidents, yet 47% of organizations currently have no AI-specific security controls in place, despite 69% naming AI data leakage as their primary security concern.
Side-by-Side: Traditional DLP vs. AI DLP
The comparison below maps each control across the six dimensions that matter most for an enterprise security evaluation. It is structured to support a direct architectural assessment rather than a feature-by-feature product comparison.
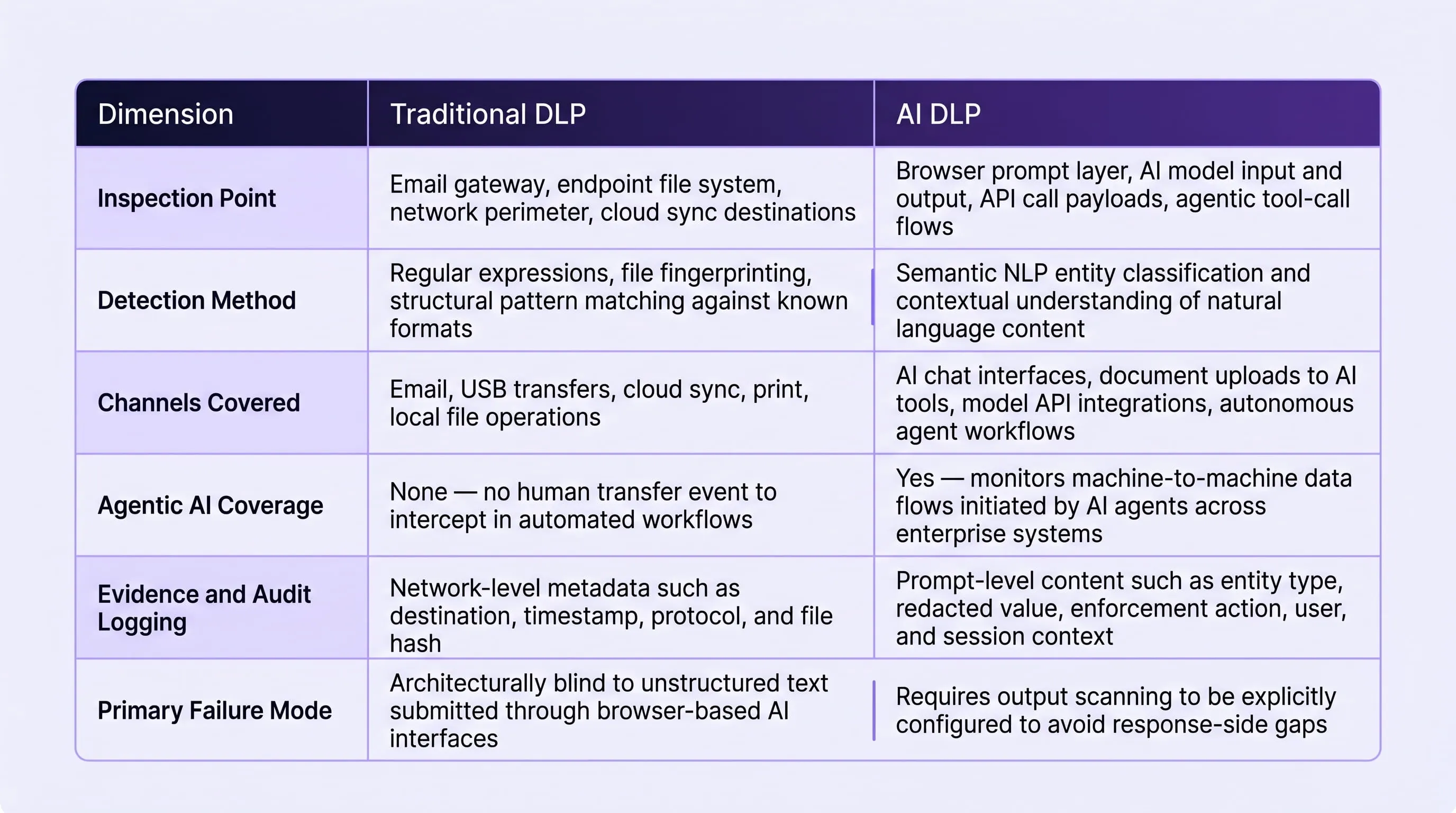
Understanding the Coverage Split in Your Security Stack
The most operationally useful way to evaluate the two controls is not to compare them against each other, but to map which data surfaces each one is designed to govern. The goal is complete coverage across all data movement vectors, not redundancy of coverage in one area while another remains unaddressed.
What Traditional DLP Continues to Protect Effectively
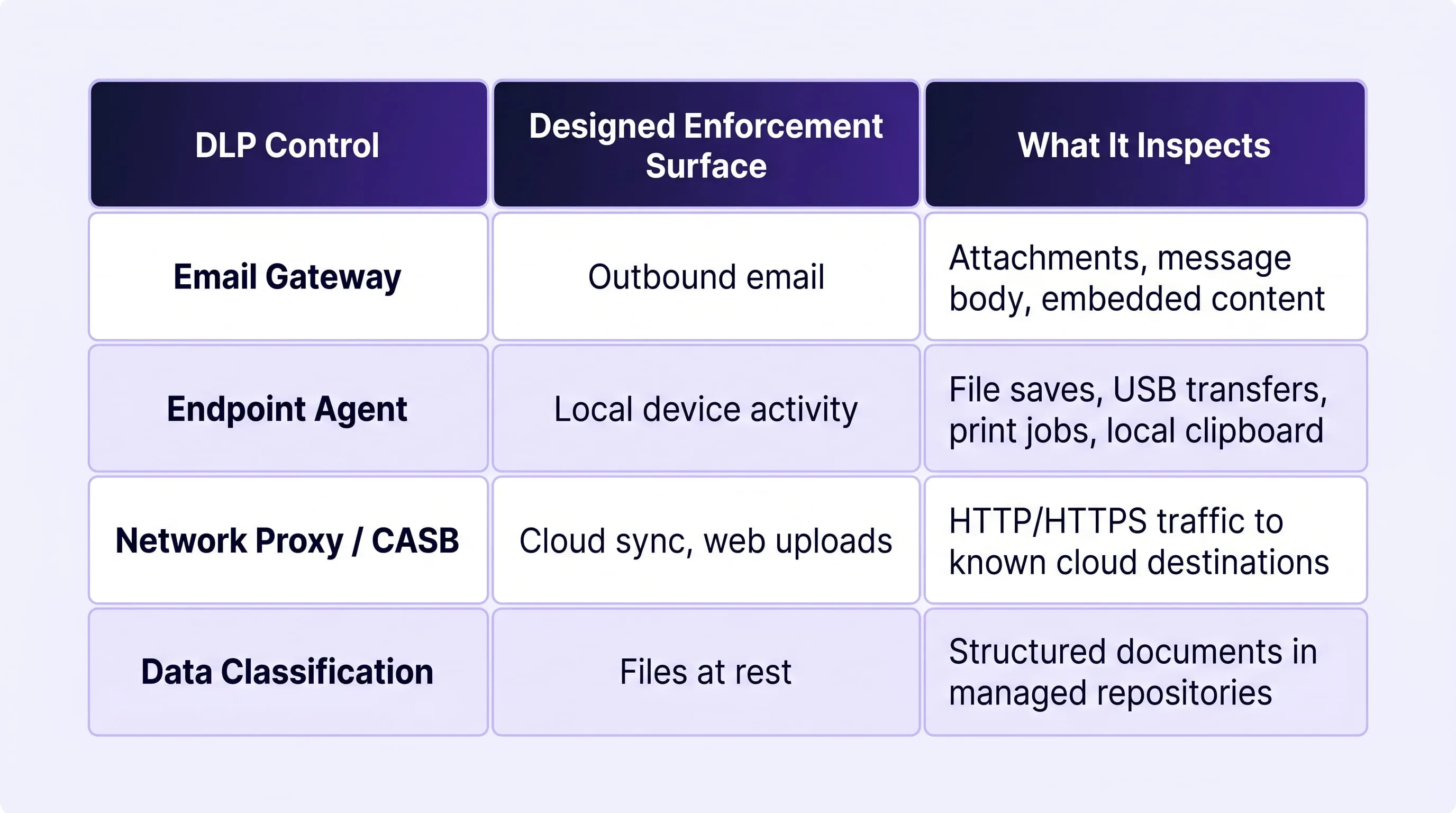
Traditional DLP remains the appropriate and effective control for the following data surfaces, and no AI DLP deployment changes that:
- Outbound email: attachments, message bodies, embedded content leaving the corporate mail system
- Endpoint file activity: saves to unmanaged devices, USB transfers, unauthorized print jobs, local clipboard monitoring outside of browser contexts
- Cloud storage synchronization: data moving from managed corporate storage to personal or unsanctioned cloud destinations
- Network egress to known destinations: HTTPS uploads to file sharing services, FTP transfers, web form submissions outside of AI tool contexts
- Data classification at rest: structured documents in managed repositories, SharePoint, OneDrive, and enterprise content management systems
What AI DLP Is Purpose-Built to Cover
The following surfaces are outside the design scope of traditional DLP and require AI DLP as the governing control:
- Natural language prompt submissions to AI chat interfaces, regardless of whether the data originated as a file or was typed directly
- Document and file uploads to AI tools where the data enters a model context rather than a conventional file transfer channel
- AI-generated responses that may surface sensitive information inferred or retrieved by the model during processing
- Autonomous AI agent workflows where data moves between enterprise systems and external models without human intervention or a discrete transfer event
- Shadow AI tool usage through personal accounts and unsanctioned platforms that fall outside network-level policy enforcement
Coverage Mapping Across Your Security Stack
The table below illustrates how traditional DLP and AI DLP divide responsibility across the full enterprise data movement surface. The objective is not to identify where one replaces the other, but to confirm that no surface is left without a governing control.
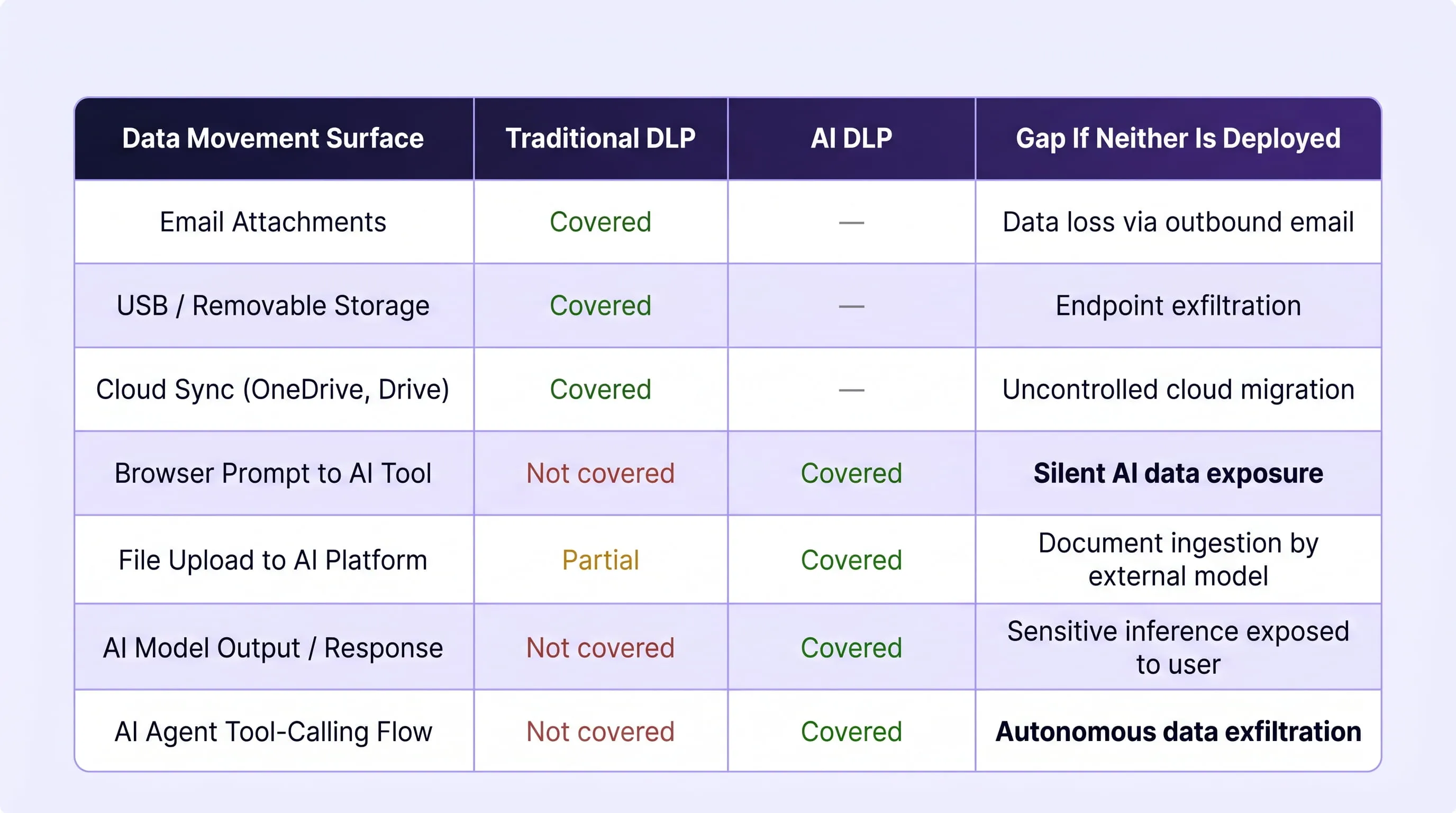
Why AI DLP Complements, Not Replaces, Your Existing DLP Investment
AI DLP addresses a specific gap that emerged when generative AI tools introduced a data movement channel that traditional DLP architectures were not instrumented to observe — and that is precisely the boundary of its purpose.
The email gateway, endpoint agent, and network proxy controls that govern file transfers, USB activity, and cloud synchronization remain valid and necessary regardless of how AI adoption evolves within the enterprise.
Enterprise DLP programs in 2026 must cover significantly more than email and USB channels, as sensitive data now moves through cloud collaboration platforms, SaaS applications, and generative AI prompts channels where legacy DLP provides limited or no visibility.
The appropriate response to that finding is to extend coverage to the AI channel, not to redirect investment away from the surfaces traditional DLP already governs effectively. Adding AI DLP to an existing security stack is an additive architectural decision, one that closes a defined gap rather than replacing a working control.
For organizations evaluating where to begin, the most defensible starting point is to audit actual AI data flows against existing DLP coverage maps, identify which AI interaction surfaces currently have no governing control, and deploy AI DLP specifically against those gaps. For a detailed mapping of how real-time prompt filtering works alongside your existing security controls, and how shadow AI discovery feeds directly into AI DLP policy enforcement, both are addressed in depth as part of LangProtect's architectural documentation.
From a standards perspective, the NIST AI Risk Management Framework's Govern and Protect functions explicitly frame AI data controls as complementary to, not substitutes for, existing organizational risk management programs, reinforcing that AI DLP should be evaluated as a targeted addition to the enterprise security architecture rather than a wholesale replacement of established controls.
How Does AI DLP Actually Work?
AI DLP operates as an enforcement layer positioned between the employee and the AI tool, intercepting the prompt before it is transmitted, classifying its content through semantic entity detection rather than pattern matching, applying a graded enforcement action based on policy, and scanning the model's response before it is returned to the user. The entire sequence occurs inline, within the active request-response cycle, before sensitive data has the opportunity to reach an external model.
The Enforcement Architecture Operating Between User and Model
The architectural position of AI DLP is what distinguishes it from every other control in the enterprise security stack. Rather than sitting at a perimeter boundary and observing traffic after it has been composed, AI DLP operates at the point of composition between the user interface and the model API endpoint where it has full visibility into prompt content before any data has left the organization's control boundary.
Traditional security tools are not designed to inspect prompts, responses, or AI-driven decisions, leaving the AI execution layer without any governing control. AI DLP addresses this specifically by enforcing security policies at execution time when AI applications interact with real inputs, real data, and real workloads rather than during development or testing phases where the actual risk does not yet exist.
LangProtect's enforcement architecture reflects this positioning directly. LangProtect Armor applies inline runtime enforcement during live request-response cycles, scanning prompts, context, and outputs to prevent harmful behavior before it reaches business systems — and extends this coverage to autonomous agent and MCP-connected workflows where traditional DLP controls have no visibility.
The Four-Step Enforcement Sequence
The enforcement process follows a defined sequence that applies to every AI interaction, regardless of the tool, the user, or the sensitivity of the content. The sequence is designed to be comprehensive — covering input and output — while operating at latency levels that have no measurable impact on the employee's experience.
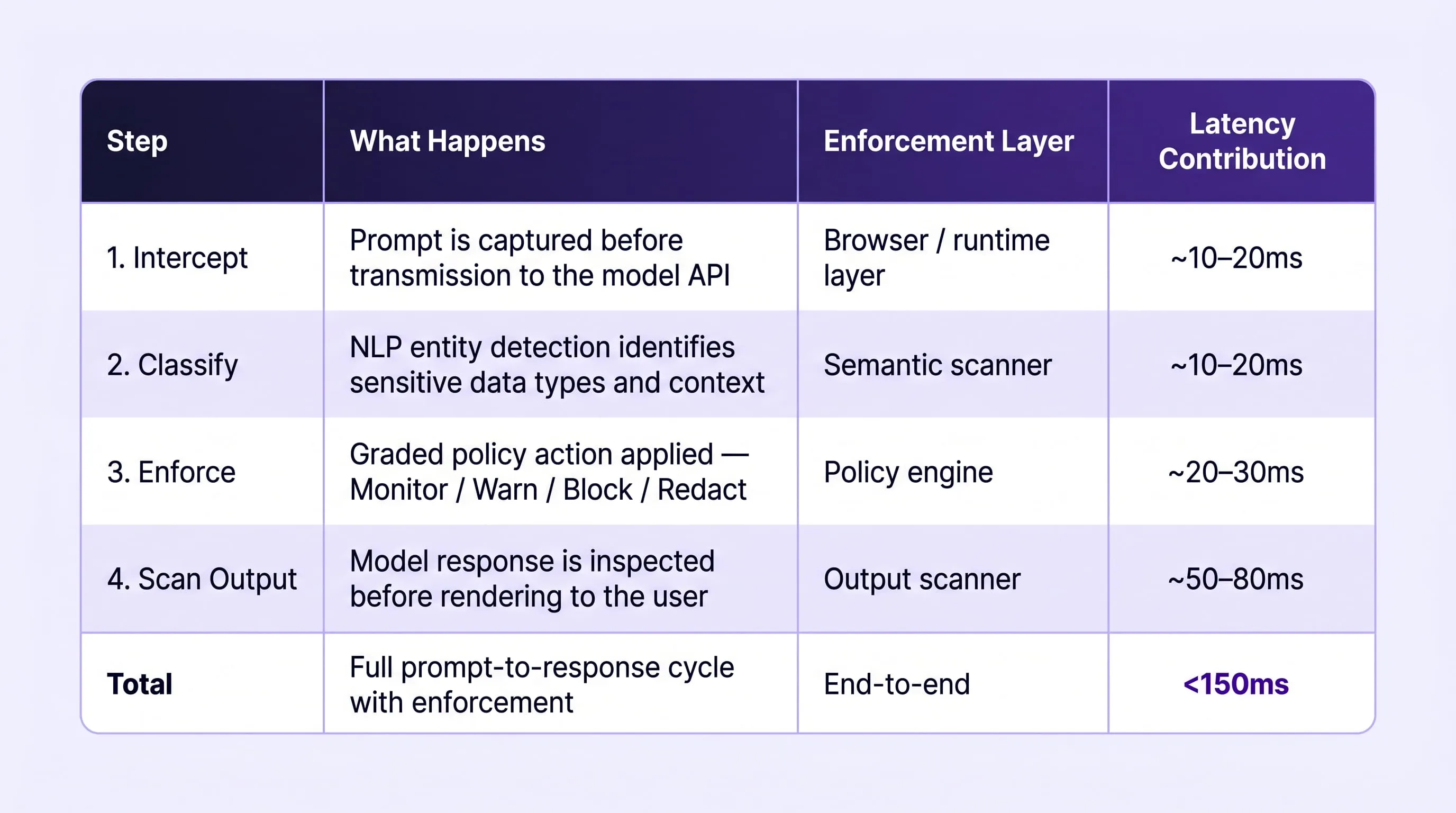
Step 1: Prompt Interception at the Browser Layer
The first step in the enforcement sequence is interception, capturing the prompt at the browser or application layer before it is transmitted to the external model. This is the only point in the data flow where the full content of the prompt is available for inspection, and it is therefore the only point at which enforcement can be applied before data leaves the organization's control boundary. Enforcement that occurs at the network layer or downstream of this point is operating after the data has already been composed and, in many architectures, after it has already left the device.
Step 2: Semantic Entity Classification
Once the prompt has been intercepted, the content is passed through a semantic classification engine that identifies sensitive data types based on meaning and context rather than structural pattern recognition. This distinction is operationally significant: a name and a number appearing in a clinical note carries an entirely different risk profile than the same name and number appearing in a generic document reference, and pattern matching cannot make that distinction without semantic understanding of the surrounding context.
LangProtect's PHIScanner identifies entity types with clinical-grade accuracy even when sensitive identifiers such as patient names are embedded within broader clinical narratives producing a Confidence Score of 99 for entity classification, which enables the policy engine to make enforcement decisions with a high degree of precision and minimal false positive generation.
Step 3: Graded Policy Enforcement Actions
Following classification, the policy engine applies an enforcement action calibrated to the risk level of the detected content and the organizational policy in effect for that data type, user role, and AI tool. The graded enforcement model is a deliberate design choice that distinguishes AI DLP from legacy blocking approaches. A binary block-or-allow architecture treats all sensitive data identically regardless of context, producing enforcement outcomes that are either too permissive to be effective or too restrictive to be operationally sustainable.
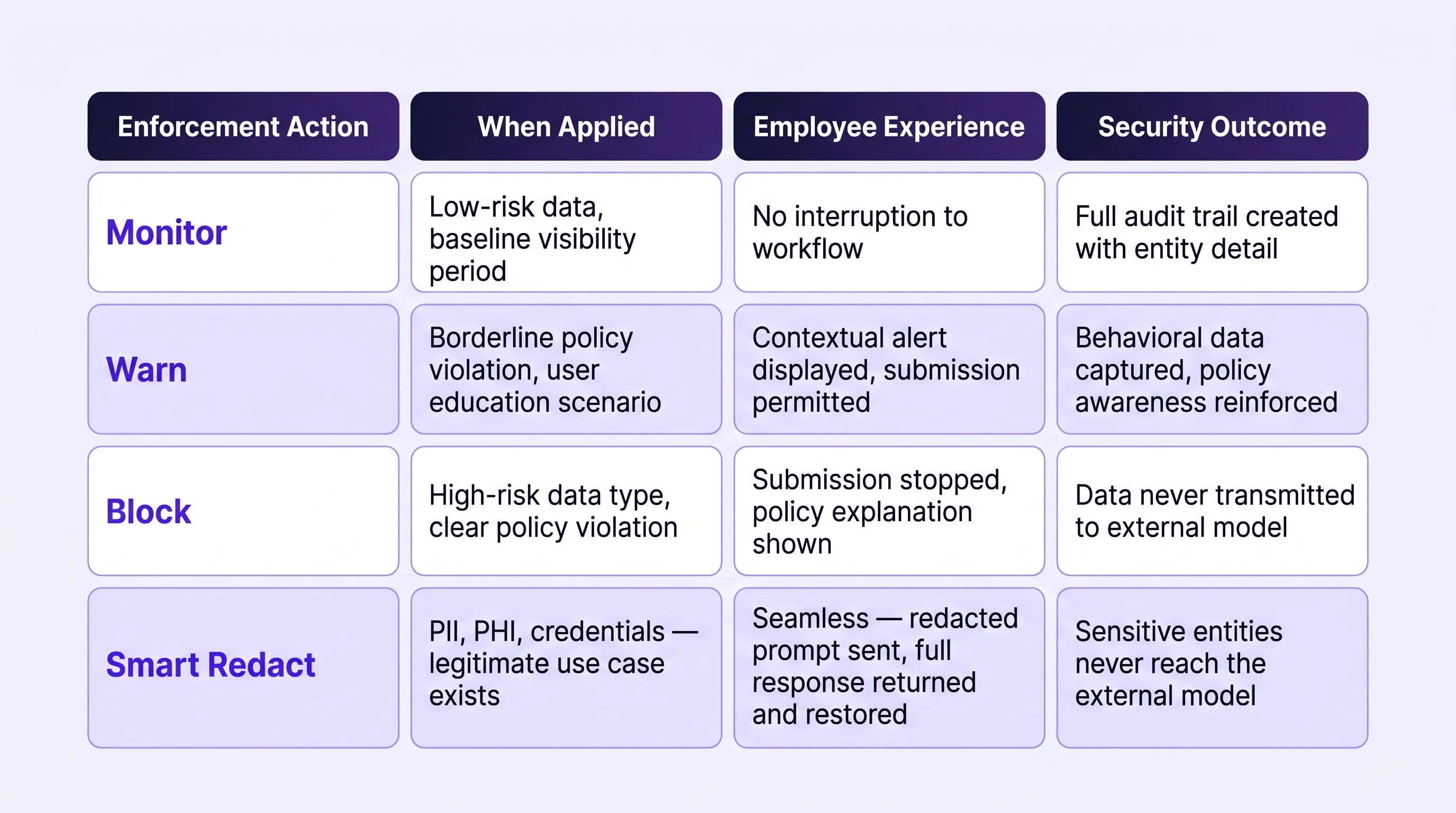
Smart Redact warrants particular attention as an enforcement mechanism because it resolves the fundamental tension between productivity and data protection. When an employee has a legitimate reason to interact with an AI tool using content that contains sensitive entities, hard blocking removes the business value entirely and drives users toward unsanctioned alternatives.
Smart Redact replaces sensitive entities with structured tokens before the prompt is transmitted, allows the model to process the sanitized content, and restores the original values in the response before it is displayed so the employee receives a complete, useful output while the sensitive data has never left the organization's control.
For a detailed examination of how real-time prompt filtering operates in practice and the technical architecture behind LangProtect's enforcement pipeline, the full implementation breakdown is covered separately.
Step 4: Output and Response Scanning
The final step in the enforcement sequence addresses a risk that is frequently overlooked in AI DLP implementations: the model's response itself. An external model that has been provided with retrieval context, has access to indexed knowledge bases, or has been fine-tuned on enterprise data may surface sensitive information in its output even when the input prompt contains no sensitive data.
Output scanning applies the same semantic classification pipeline to the model's response before it is rendered to the user, ensuring that data the model has inferred, retrieved, or surfaced from its context is subject to the same policy enforcement as the input.
What This Looks Like in the LangProtect Dashboard
The abstract enforcement sequence above translates into a concrete, observable event record in the LangProtect Guardia dashboard. Guardia provides a live dashboard of every AI tool in use across the organization, not merely which user accessed which system, but the actual prompt content, what was typed, what was uploaded, and what the model responded with.
Each enforcement decision is captured as a structured event that contains the information a security or compliance team needs to investigate, audit, and demonstrate regulatory adherence.
The following represents a real enforcement event as it appears in the Guardia monitoring console:
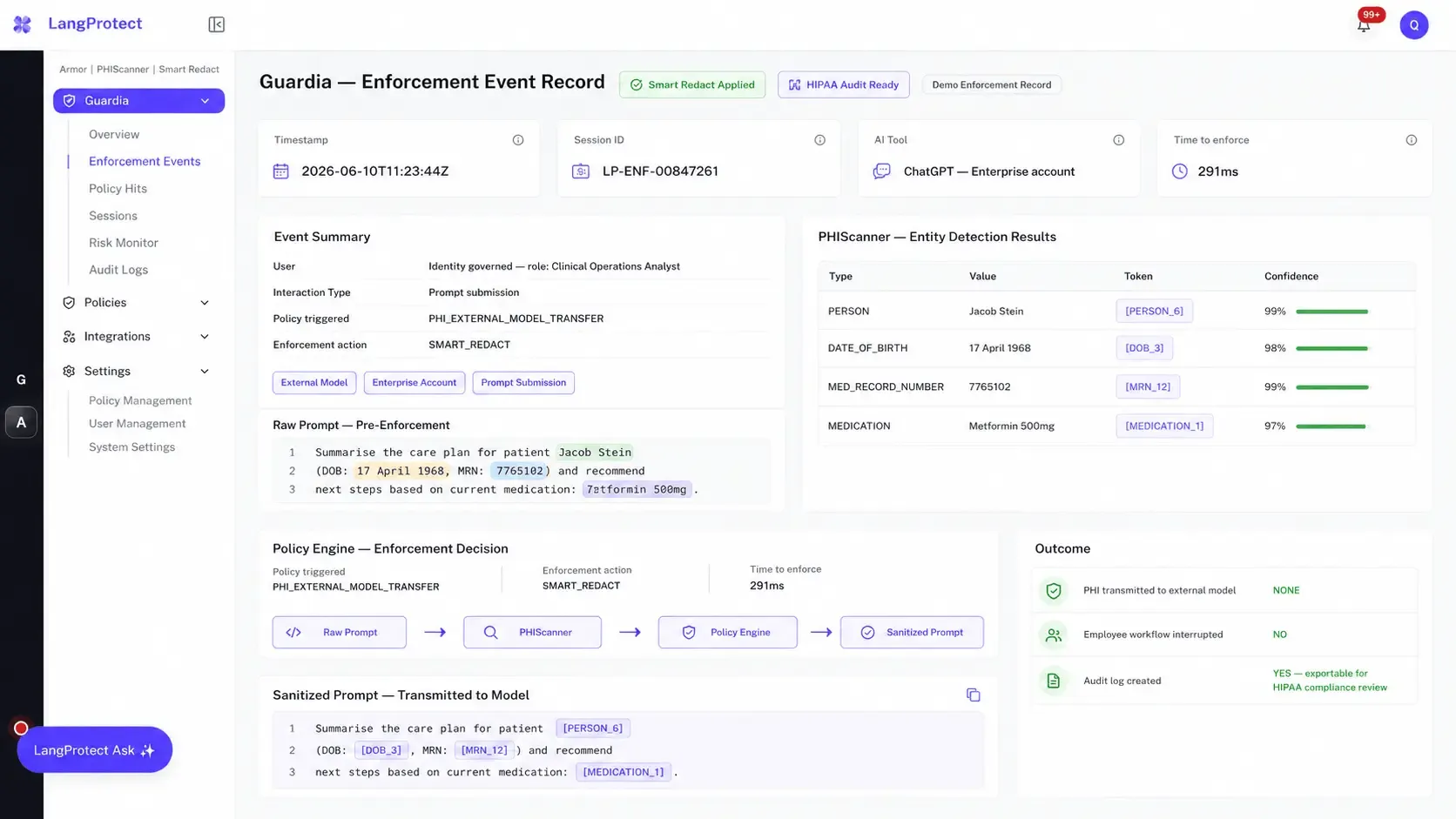
// LangProtect Guardia — Enforcement Event Record
// LangProtect Armor | PHIScanner | Smart Redact
Timestamp: 2026-06-10T11:23:44Z
Session ID: LP-ENF-00847261
User: [Identity governed — role: Clinical Operations
Analyst]
AI Tool: ChatGPT (chat.openai.com) — Enterprise account
Interaction Type: Prompt submission
// Raw prompt (pre-enforcement)
"Summarise the care plan for patient Jacob Stein
(DOB: 17 April 1968, MRN: 7765102) and recommend
next steps based on current medication: Metformin 500mg."
// PHIScanner — Entity Detection Results
Entity 1 | Type: PERSON | Value: Jacob Stein |
Token: [PERSON_6] | Confidence: 99
Entity 2 | Type: DATE_OF_BIRTH | Value: 17 April 1968 |
Token: [DOB_3] | Confidence: 98
Entity 3 | Type: MED_RECORD_NUMBER | Value: 7765102 |
Token: [MRN_12] | Confidence: 99
Entity 4 | Type: MEDICATION | Value: Metformin 500mg |
Token: [MEDICATION_1]| Confidence: 97
// Policy Engine — Enforcement Decision
Policy triggered: PHI_EXTERNAL_MODEL_TRANSFER
Enforcement action: SMART_REDACT
Time to enforce: 291ms
// Sanitized prompt (transmitted to model)
"Summarise the care plan for patient [PERSON_6]
(DOB: [DOB_3], MRN: [MRN_12]) and recommend
next steps based on current medication: [MEDICATION_1]."
// Outcome
PHI transmitted to external model: NONE
Employee workflow interrupted: NO
Audit log created: YES — exportable for HIPAA
compliance review
Within 150 milliseconds, the interaction moves from a critical threat classification to sanitized context; the employee receives a complete, clinically relevant response, and no protected health information has reached the external model at any point in the transaction.
The audit log entry generated by this event contains the entity types detected, the confidence scores assigned, the enforcement action applied, and the session context all of which are directly relevant to a HIPAA audit, an EU AI Act Article 12 evidence request, or an internal compliance review.
Why Graded Enforcement Outperforms Binary Blocking
Organizations that deploy AI DLP as a hard-block control encounter a predictable and well-documented outcome: employees route sensitive workflows through personal accounts, unmanaged browser extensions, or unsanctioned AI tools that sit entirely outside enterprise visibility.
The resulting security posture is measurably worse than the one that existed before the block was applied, because the data is still entering AI tools; it is simply entering ones the organization can no longer monitor or govern. The specific risk this creates is examined in detail in LangProtect's analysis of shadow AI usage and why blocking accelerates it.
Graded enforcement resolves this by calibrating the response to the actual risk level of each interaction Monitor for baseline visibility, Warn to redirect at the moment of risk, Block for clear policy violations, and Smart Redact for legitimate workflows involving sensitive entities. Employees remain within governed channels, sensitive data remains under organizational control, and the protection posture is both more secure and operationally sustainable than a binary approach.
From a standards perspective, the OWASP LLM Top 10's guidance on Sensitive Information Disclosure (LLM06) explicitly identifies the absence of output filtering and prompt-level controls as the primary contributing factors to this risk category reinforcing that a complete AI DLP implementation must address both the input and output surfaces of every AI interaction, not only the point of prompt submission.
How Should You Evaluate an AI DLP Tool?
Evaluating an AI DLP solution requires moving beyond feature lists and examining three foundational questions: where enforcement actually occurs in the data flow, how the classification engine distinguishes sensitive from non-sensitive content in natural language, and whether the audit evidence the tool produces satisfies the specific regulatory requirements your organization operates under. Vendors that cannot answer all three questions precisely represent an architectural gap in their approach, not a configuration difference.
The 7-Point AI DLP Evaluation Checklist
The criteria below are structured to support a direct vendor assessment conversation. Each criterion maps to a specific architectural requirement, not a preference and the "Why It Matters" column identifies the operational consequence of a gap in that area.
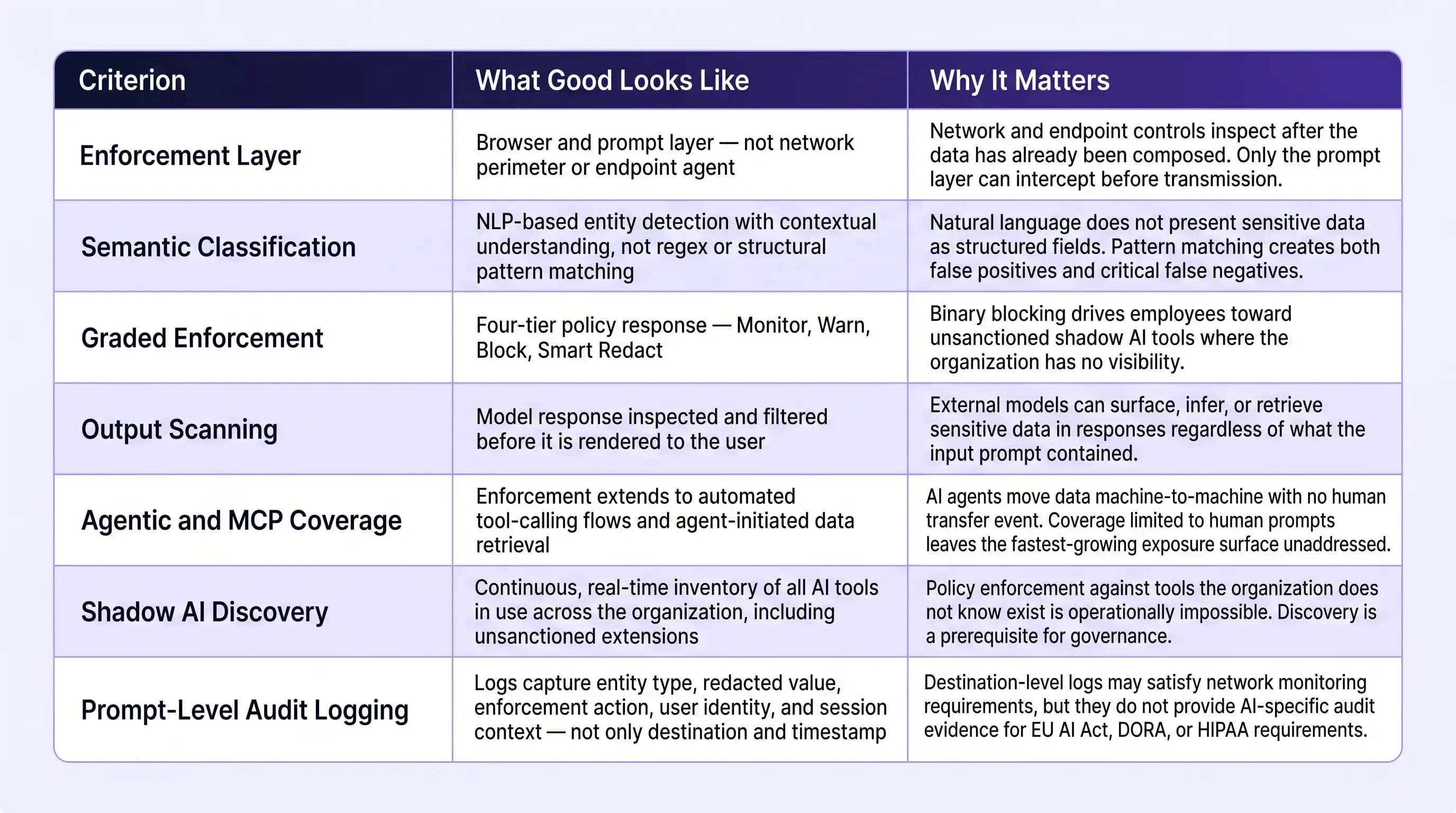
The One Question That Filters Most Vendors
"Where does enforcement actually happen: at the network, the endpoint, or the browser prompt layer?"
This question should be the first one asked in any AI DLP vendor evaluation because it resolves the most consequential architectural difference between solutions more efficiently than any other line of questioning.
A vendor whose enforcement occurs at the network proxy layer is inspecting traffic metadata destination, protocol, timestamp but not prompt content. A vendor whose enforcement occurs at the endpoint agent level is monitoring device-level file activity, not browser interactions. Only a vendor whose enforcement operates at the browser or prompt layer has visibility into the actual content of what is being submitted to the model, which is the only point at which data protection policy can be meaningfully applied.
The NIST AI Risk Management Framework's Govern and Protect functions provide the governance foundation for structuring this evaluation against organizational risk tolerance, while the IBM Cost of a Data Breach Report supplies the business-case context, an average breach cost of $4.88 million that frames the investment decision for leadership conversations. For organizations that have previously deployed blanket AI blocking policies and encountered the shadow AI escalationthat typically follows, the evaluation checklist above also functions as a remediation roadmap: each criterion it identifies as absent in the current environment represents a discrete gap that a purpose-built AI DLP deployment needs to close.
Frequently Asked Questions
Q: What is AI DLP?
A: AI DLP (AI Data Loss Prevention) is a security control purpose-built to monitor and enforce policy on sensitive data as it flows into and out of AI tools, at the prompt, the file upload, and the model response. Unlike traditional DLP, which governs data at email gateways, endpoints, and cloud sync boundaries, AI DLP operates at the browser and prompt layer where AI interactions are composed and where conventional controls have no visibility into content.
Q: How is AI DLP different from traditional DLP?
A: The distinction is architectural rather than cosmetic. Traditional DLP inspects data as a structured object crossing a known transfer boundary, using pattern matching to identify sensitive formats. AI DLP inspects live prompt and response content using semantic entity classification, it understands what the data means in context, not simply what it looks like structurally. The two controls operate at different points in the data flow and govern different surfaces, which is why each requires the other to produce complete enterprise coverage.
Q: Does AI DLP replace my existing DLP?
A: No, and any vendor positioning AI DLP as a wholesale replacement for traditional DLP is misrepresenting the scope of the problem it solves. Traditional DLP continues to be the appropriate control for email exfiltration, endpoint file transfers, USB activity, and cloud synchronization events, risks that remain valid regardless of how AI tool adoption evolves. AI DLP closes the specific gap that emerged when generative AI introduced a data movement channel that traditional DLP was never designed to observe. The two controls are complementary, governing distinct surfaces within the same enterprise security stack.
Q: Where does AI DLP enforcement happen: at the network, endpoint, or browser?
A: Effective AI DLP enforcement must occur at the browser or prompt layer, the only point in the data flow where prompt content is available for inspection before it leaves the device. Network-layer controls observe traffic metadata including destination and protocol, but do not have visibility into what is inside the prompt. Endpoint-layer controls monitor device-level file activity, but do not inspect browser interactions. Enforcement that occurs downstream of the prompt layer has already lost the opportunity to prevent the data from reaching the external model.
Q: Can AI DLP cover AI agents as well as human-initiated prompts?
A: It must, and any AI DLP implementation that limits enforcement to human-initiated interactions has a material gap in its coverage. AI agents operating within enterprise environments move data machine-to-machine, querying internal knowledge bases, retrieving records from connected systems, and passing outputs to external models without generating the human transfer events that perimeter DLP tools are designed to intercept. Effective AI DLP must extend enforcement to automated tool-calling flows and agent-initiated data retrieval as a baseline capability, not an optional addition.
Q: Does AI DLP slow employees down?
A: A well-implemented AI DLP deployment adds enforcement latency measured in milliseconds, well below the threshold of perceptible delay in normal workflows. LangProtect's enforcement pipeline, for example, completes the full prompt interception, entity classification, policy enforcement, and audit logging sequence in under 300 milliseconds. Clean prompts that contain no sensitive entities pass through the enforcement layer without any interruption. Enforcement actions only fire on policy violations, and graded responses; warn before block, redact rather than reject; are designed specifically to maintain workflow continuity while ensuring that sensitive data does not reach the external model.
Q: What should I look for when evaluating an AI DLP tool?
A: The single most important question to ask any AI DLP vendor is where enforcement actually occurs in the data flow' at the network layer, the endpoint, or the browser prompt layer. The answer to that question determines whether the tool has genuine visibility into prompt content before it reaches the model or is operating too late to prevent transmission. Beyond enforcement layer, the evaluation should assess semantic classification depth, graded enforcement capability, output scanning coverage, agentic and MCP workflow support, shadow AI discovery, and whether the audit log format satisfies the specific regulatory requirements' EU AI Act Article 12, HIPAA, DORA. that apply to your organization.
Securing the Channel Your DLP Was Never Built For
The data security perimeter has always expanded to follow the channels through which enterprise data moves from physical media, to email, to cloud storage, and now to the AI prompt layer. The controls that protect each channel have never been interchangeable, and the emergence of generative AI as a primary data movement surface is not an exception to that pattern.
Traditional DLP continues to govern the channels it was designed for with precision; what it cannot do is observe a browser prompt, classify natural language semantically, or enforce policy at the point where an employee's intent meets an external model and that is the surface where the exposure now exists.
As AI agents take on increasingly autonomous roles within enterprise workflows, the prompt channel will grow in both volume and complexity, moving further beyond what perimeter controls were built to address.
The organizations that establish AI DLP as a governing layer now before agentic adoption scales and before a regulatory audit or breach incident forces the conversation will be the ones with the forensic trail, the enforceable policy record, and the architectural foundation to govern AI adoption without constraining it.
Book a 30-Minute AI Security Review
See exactly what sensitive data is flowing through your organization's AI tools; and how LangProtect closes the gap your existing DLP cannot see.


