
Is Your RAG Knowledge Base Leaking Confidential Documents Right Now?


A legal team deploys an internal AI assistant to help lawyers identify relevant case precedents. Three months into the deployment, a routine compliance review surfaces an unexpected finding: junior associates have been receiving AI-generated responses that include confidential partner-level matter files, board-level strategic documents, and unreleased acquisition targets none of which those associates were authorised to access under the firm's document governance framework.
The security monitoring infrastructure generated no alert throughout this period. No access violation was recorded in the SIEM. No policy was breached by the employees submitting the queries, and no anomaly was flagged in the retrieval logs because no retrieval-layer logging existed.
The AI assistant performed precisely as its architecture intended, identifying the most semantically relevant documents in the knowledge base and incorporating them into its responses, without any mechanism to evaluate whether the querying user held the necessary permissions to view those documents.
This pattern is not exceptional. Across enterprise RAG deployments that LangProtect has assessed, retrieval oversharing events occur consistently and in the majority of organisations, the absence of retrieval-layer audit logging means the exposure has been ongoing for weeks or months before any internal review identifies it.
For organisations that have deployed a RAG-based AI assistant, an internal knowledge base search tool, or an AI-powered document retrieval system, this guide sets out what is likely occurring inside that deployment today.
It covers the two distinct mechanisms through which enterprise RAG systems leak sensitive data, the structural reasons why conventional security controls cannot detect either of them, and the four technical controls that address both threat models before a regulatory assessment or security incident makes the gaps visible to someone else.
Not Sure if Your RAG System Has This Exposure?
Most organisations do not identify retrieval oversharing or knowledge base integrity failures until a compliance review or an incident investigation requires them to look.
A 30-minute RAG security assessment with the LangProtect team identifies the specific gaps in your deployment before that point.
What Is RAG Data Leakage and why does your security stack not see it?
RAG data leakage occurs when a retrieval-augmented generation system returns sensitive documents or information to a user who was never authorised to access them and produces no alert, no DLP flag, and no anomaly in any security monitoring tool your organisation currently operates.
Unlike prompt-based data leakage, which originates at an employee's browser when sensitive information is submitted to an external AI model, RAG data leakage originates inside your own AI system's retrieval infrastructure placing it entirely outside the visibility of the controls positioned at your environment's boundary with external services.
How Does a RAG System Actually Work?
A RAG system combines three components to generate AI responses from your internal documents:
-
The knowledge base - the internal document repository your AI system retrieves from. This contains your organisation's sensitive data: financial records, legal documents, HR files, strategic plans, client contracts, and any other content that has been indexed for retrieval.
-
The retrieval engine - the component that searches the knowledge base in response to a user query. It identifies the most semantically relevant document chunks and passes them to the language model. In most enterprise RAG deployments, the retrieval engine operates without any awareness of user permissions, document classification levels, or access governance policies.
-
The language model - the AI component that generates a response using the retrieved content as context. The model does not know whether the retrieved documents were authorised for the querying user. It generates a response from what it was given.
The security gap exists in the retrieval engine, the component that decides what gets surfaced. Closing that gap is what RAG security requires.
What Are the Two Types of RAG Data Leakage?
Enterprise RAG systems leak sensitive data through two distinct mechanisms. Understanding the difference is critical because each one requires a different technical control to prevent.
-
RAG oversharing - an architectural failure. The retrieval engine surfaces documents a querying user was never authorised to see because access controls are applied at the application layer rather than at the retrieval layer where documents are actually selected. No attacker is involved. The system is functioning exactly as designed. The failure is in how the architecture was built.
-
RAG poisoning - an adversarial attack. A threat actor injects malicious or misleading content into the knowledge base, causing the retrieval system to surface and incorporate that content into AI-generated responses and potentially to exfiltrate other sensitive documents in the process. The attacker does not need access to the AI model itself. They need write access to any document source the knowledge base ingests from.
Both mechanisms produce data leakage. Both are invisible to standard security monitoring. Both are addressed in this guide.
Why Cannot Your Existing Security Controls Detect RAG Data Leakage?
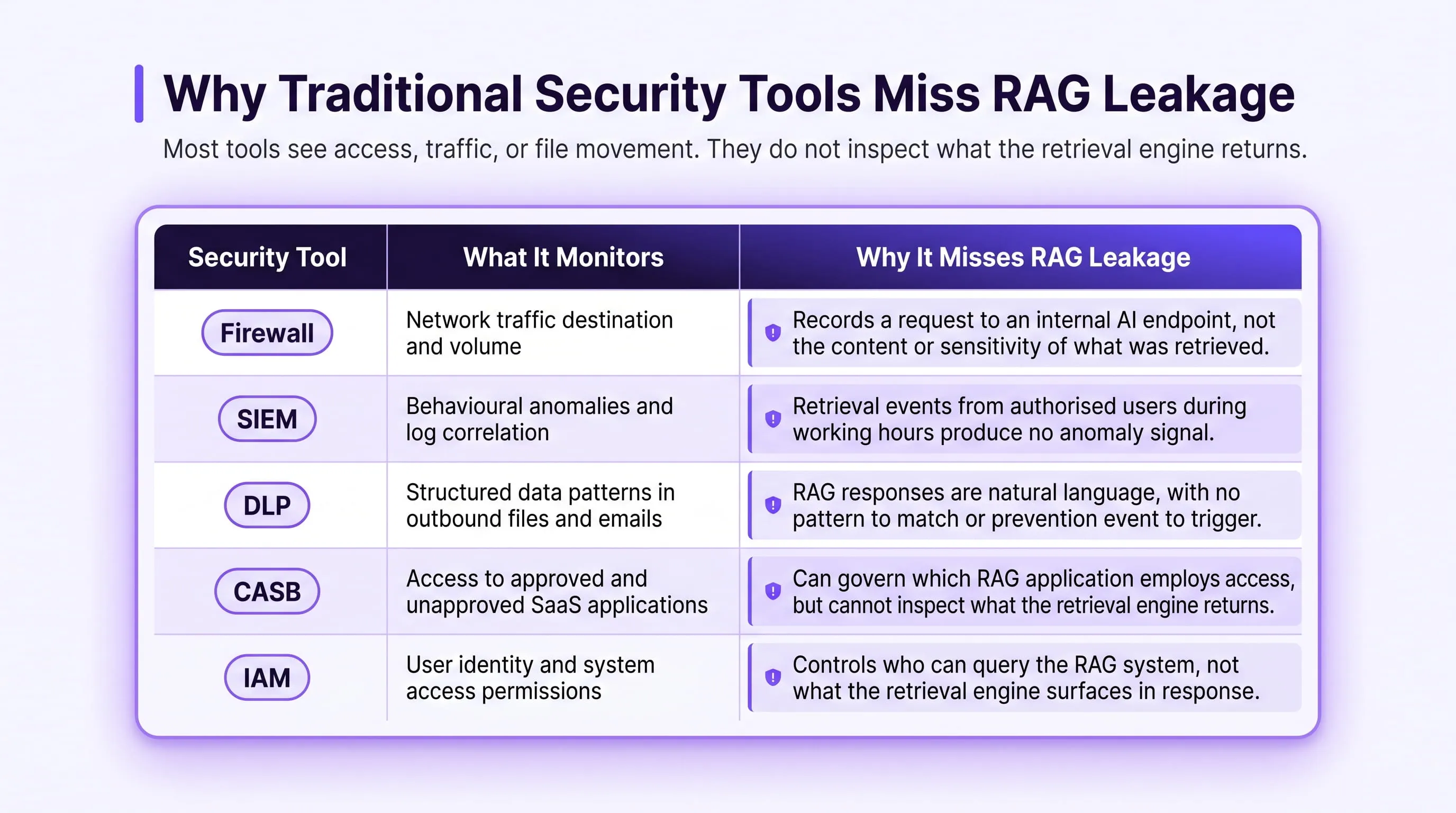
The structural reason that conventional security tools miss RAG data leakage is that each tool was designed to monitor a different layer of the technology stack and the retrieval layer, where RAG data leakage actually occurs, falls into a gap none of them were built to cover.
Firewalls and network monitoring tools observe traffic at the perimeter. When a RAG system retrieves a board-level financial document and incorporates it into an AI response, the network layer records an internal request to an AI API endpoint. The content of that retrieval event and the sensitivity of the documents involved are entirely outside what network monitoring was designed to capture.
SIEM platforms collect and correlate log data to identify behavioural anomalies, unusual access patterns, authentication failures, or activity outside normal working hours. A retrieval event that surfaces an executive-level strategic document to a junior analyst occurs during normal working hours, through an authorised application, submitted by an authenticated user. It produces no anomaly because from the SIEM's perspective, nothing anomalous occurred.
Data Loss Prevention tools scan outbound data for structured patterns account numbers, social security numbers, and other recognisable data formats. A RAG response containing confidential merger target information or privileged legal advice is composed of natural language. It contains no structured pattern that DLP was designed to recognise, and it reaches the employee's screen without generating a prevention event of any kind.
The table below maps each conventional security tool against the specific RAG data leakage event it cannot detect:
What Are the Compliance Consequences of RAG Data Leakage?
The regulatory consequences of undetected RAG data leakage are specific, measurable, and operating on a deadline that is no longer distant.
-
EU AI Act Article 12 - For any organisation operating a RAG system in a high-risk AI application category including HR decision support, credit risk assessment, healthcare diagnostics, education, or critical infrastructure management.
Article 12 requires that operators maintain logs of system inputs and outputs sufficient to enable post-hoc auditing. This means regulators will ask which documents were retrieved, in response to which queries, and what controls governed that retrieval. The enforcement deadline is August 2, 2026. Penalties reach €35 million or 7% of global annual revenue. -
GDPR Article 28 - If the documents surfaced through RAG oversharing include personal data, employee records, customer files, clinical notes and those documents were processed by an AI system operating without a valid Data Processing Agreement, the organisation may face an unauthorised processing obligation with 72-hour breach notification requirements.
-
DORA Article 28 - For financial entities subject to DORA, third-party ICT service provider contracts must include documented data flow controls and audit rights. Most RAG vendor agreements covering the vector store, embedding model, and retrieval infrastructure were not written to satisfy DORA's ICT third-party risk provisions.
Most enterprise RAG deployments currently have no logging at the retrieval layer. That absence is simultaneously a security failure and a regulatory liability that will become visible through an internal review, a vendor audit, or a National Competent Authority enforcement action within the current compliance cycle.
For a detailed breakdown of how enterprise AI security controls fail at the layer where AI data leakage occurs, see: Why AI Requires a New Security Layer Beyond Traditional Controls.
What Is RAG Oversharing and How Does It Expose Confidential Documents?
RAG oversharing occurs when the retrieval engine returns documents a querying user was never permitted to access not because of a bug, but because most enterprise RAG architectures apply access controls at the application layer while the retrieval engine operates entirely below it. The result is that confidential board reports, HR records, and strategic documents flow into AI-generated responses delivered to employees who should never have seen them.
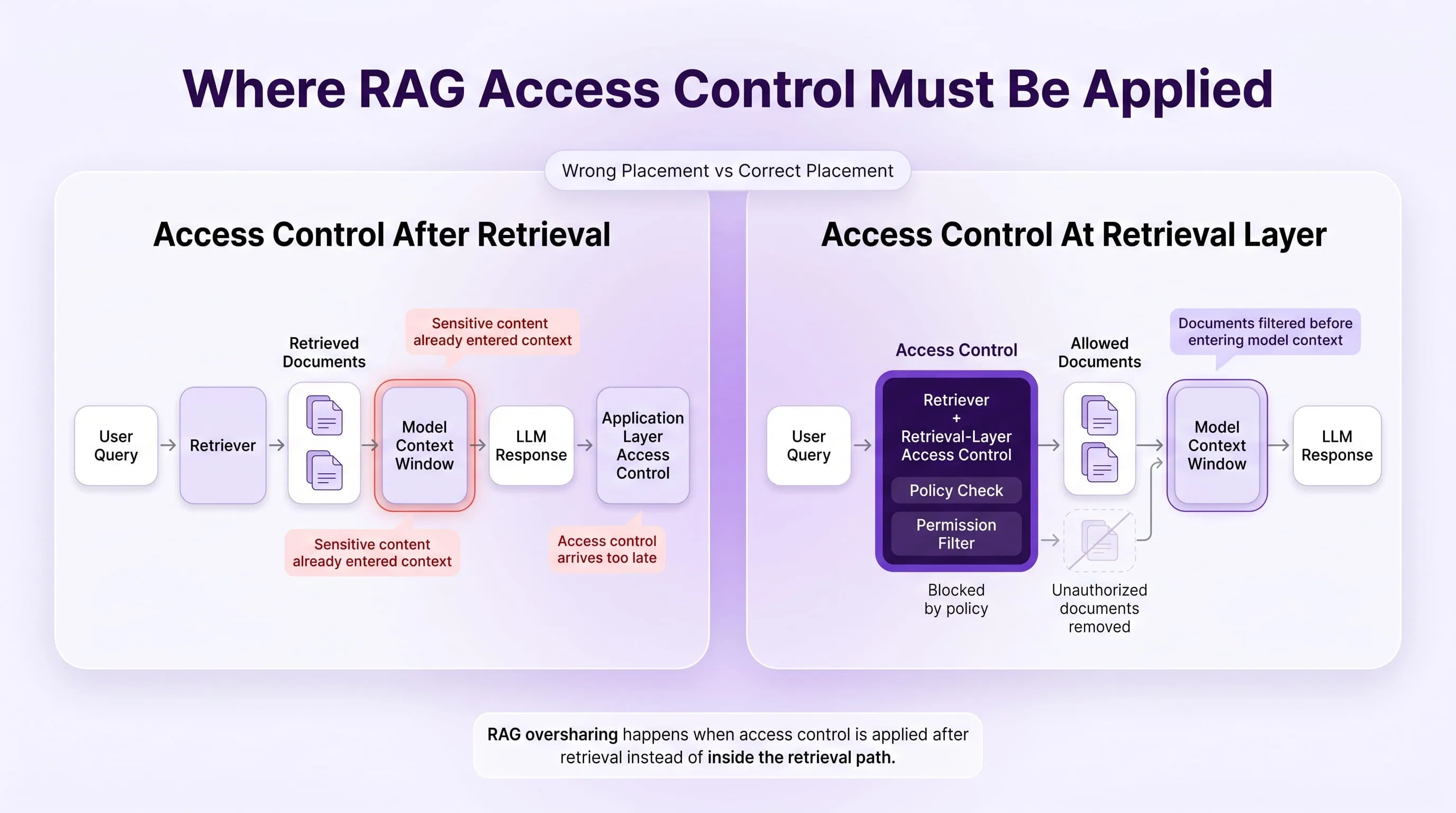
Why Does the RAG Access Control Gap Exist?
Most enterprise RAG deployments apply access controls at one of three points - none of which address the retrieval step where document selection actually occurs:
-
Application layer - determines who can submit a query. Has no influence over which documents the retrieval engine returns.
-
UI layer - restricts what employees see in the interface. Has no influence over the retrieval pipeline beneath it.
-
Post-retrieval filter - attempts to remove unauthorised content after retrieval has already run. By the time this filter fires, the document is already in the model's context window.
The permission check runs after the data has already been selected. That sequencing is the gap and closing it requires a control at the retrieval layer itself, before document chunks are passed to the language model.
What Does a RAG Oversharing Event Look Like in Practice?
Consider a financial services organisation that indexes its full internal document library into a single knowledge base client portfolios, board presentations, HR compensation data, and M&A targets. A junior analyst submits a routine query about credit risk policy.
The retrieval engine scores a board-level risk committee document as highly semantically relevant and surfaces it alongside the expected results. The analyst receives a response incorporating board-level financial projections they were never cleared to access. The application layer logs a successful query. The SIEM records no anomaly. No compliance record of the event exists.
This is the RAG system functioning exactly as designed with an architecture that was never built to ask whether the employee was authorised to receive what it retrieved.
Can Vector Embeddings Be Used to Reconstruct Confidential Documents?
Yes and this is one of the most underestimated risks in enterprise RAG security. A vector embedding is structurally analogous to a fingerprint; it cannot be read like a page of text, but a skilled analyst can use it to reconstruct identifying characteristics of the original document.
Embedding inversion works on the same principle. An attacker with query access to a RAG system submits carefully crafted queries, observes the response patterns, and progressively reconstructs document content they have never directly accessed. Peer-reviewed research from the University of Pisa confirmed this a black-box attack that extracts a private knowledge base through adaptive query generation, with no direct access to the raw document store.
The OWASP LLM Top 10 catalogues this risk under LLM08: Vector and Embedding Weaknesses as one of the most critically underestimated vulnerabilities in production RAG deployments. The security implication is direct:
- The vector index is not an anonymised derivative of your documents it is a recoverable version of them
- Access controls applied only to source documents leave the vector index unprotected and exploitable
- An internal user or external attacker with query access can attempt embedding inversion without triggering any standard security alert
- The vector store requires the same classification governance and audit logging as the source documents it was derived from
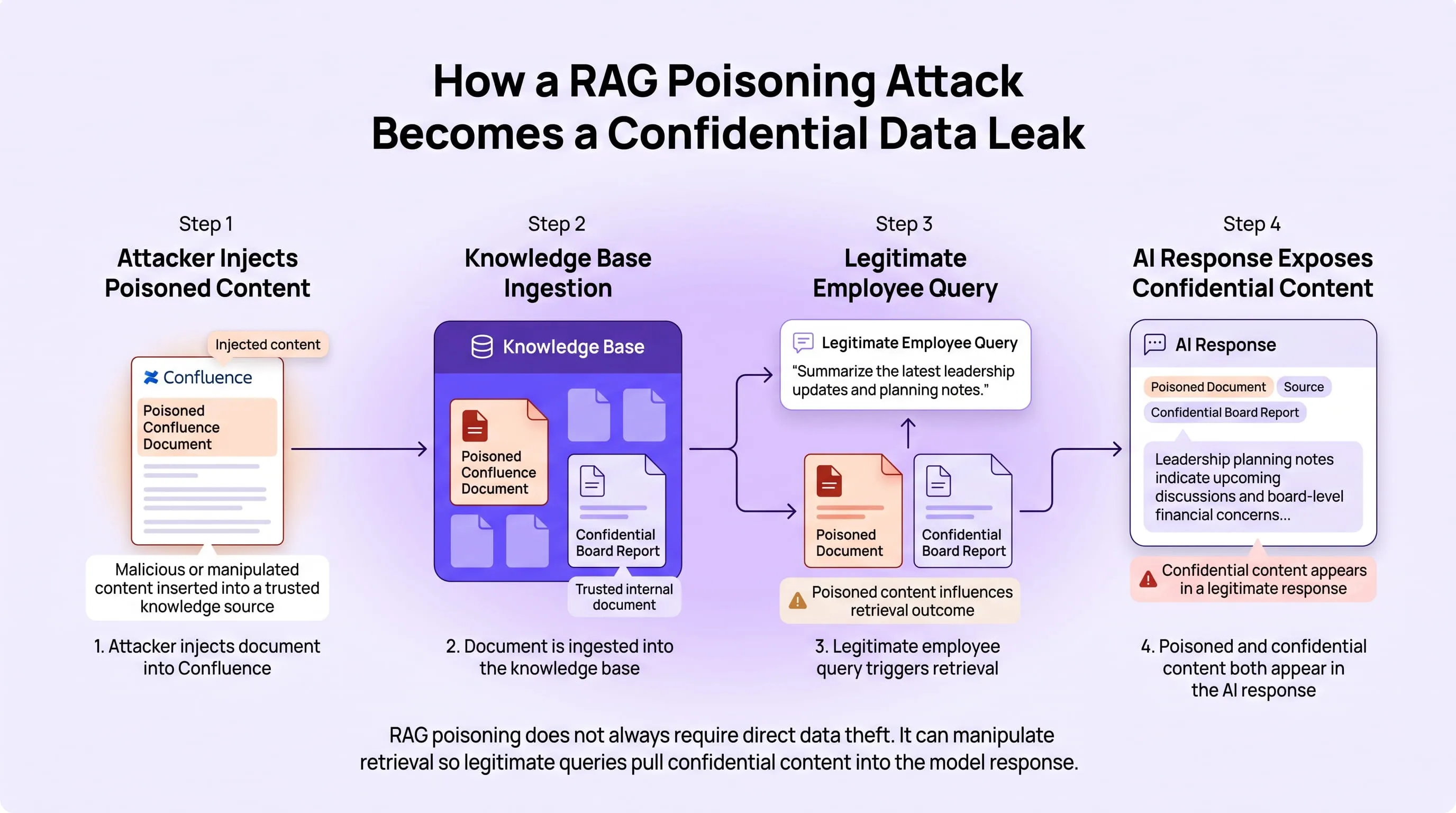
What Is RAG Poisoning and How Do Attackers Use It to Steal Enterprise Data?
RAG poisoning is an adversarial attack in which a threat actor injects malicious content into an enterprise knowledge base causing the AI assistant to retrieve and present that content as legitimate organisational information, and in more sophisticated executions, to exfiltrate other sensitive documents from the knowledge base in AI-generated responses.
What Does an Attacker Need to Execute a RAG Poisoning Attack?
The attacker does not need access to the AI model, the vector store, or the retrieval infrastructure. They need write access or the ability to influence write access to any document source the knowledge base ingests from. In most enterprise environments, that attack surface is wider than security teams recognise:
- A SharePoint library with contributor permissions open to a broad internal group
- A Confluence space where page creation is not restricted to a defined governance team
- A Google Drive folder connected to an automated ingestion pipeline
- A shared network drive mapped to a knowledge base indexing job
Document source governance is typically managed by content owners, not security teams meaning the write-access permissions that make RAG poisoning possible are rarely reviewed through a security lens.
How Does RAG Poisoning Execute in a Real Enterprise Environment?
An attacker with contributor access to a shared Confluence space creates a document that presents as a standard internal process guide. Embedded in the document is a hidden instruction directing the retrieval system to surface a confidential board financial report whenever a user queries Q3 financial performance.
The following morning, a junior analyst submits a routine question about Q3 results. The retrieval engine identifies the poisoned document as semantically relevant and surfaces it alongside the board report it referenced. Both documents enter the model context window. The analyst receives a response incorporating board-level financial projections they were never authorised to access. The attacker obtains the information without ever querying the system directly.
A successful RAG poisoning attack produces one of two outcomes and in sophisticated executions, both simultaneously:
- Integrity failure the AI assistant produces incorrect or manipulated responses based on injected content, eroding system reliability across all users
- Data exfiltration injected content causes the retrieval engine to surface and return other sensitive documents in responses delivered to legitimate users
MITRE ATLAS catalogues this attack class under its AI-specific threat matrix as a technique that exploits the trust relationship between a RAG system and its knowledge sources a trust relationship that most enterprise RAG deployments have never formally assessed or governed.
Why Is RAG Poisoning So Difficult to Detect?
RAG poisoning produces none of the signals that conventional security monitoring is designed to catch. The specific properties that make it invisible are:
- The poisoned document appears as a normal knowledge base entry, it passes standard content ingestion without triggering any integrity check
- The retrieval event is a normal internal operation the retrieval engine returns the poisoned document because it is semantically relevant, not because anything anomalous occurred
- The employee query is fully legitimate an authenticated user submitting a standard question through an approved application
- The AI response appears normal the model generates a coherent, well-structured answer that shows no surface-level sign of having been manipulated
- No security event fires at any point in the chain there is no authentication failure, no access control violation, no network anomaly, and no DLP match
The broader context that typically enables RAG poisoning where document sources are loosely governed and write access is distributed without security review is the same exposure pattern that drives shadow AI incidents in enterprise environments.
The financial and regulatory consequences of that exposure are detailed in LangProtect's analysis of what undetected AI security gaps actually cost enterprises when they surface through a breach or a compliance investigation.
Is Your RAG Pipeline Already Compromised?
An attacker with write access to any document source your RAG system ingests from can silently exfiltrate board-level documents through a legitimate employee query, and your current security stack has no mechanism to detect it.
How to Secure Your Enterprise RAG Pipeline Against Oversharing and Poisoning
Securing an enterprise RAG pipeline against both oversharing and poisoning requires four controls operating at different layers of the retrieval architecture. Each threat exploits a different gap and addressing one without the others leaves the remaining pathway open. None of these controls require rebuilding your existing RAG architecture from scratch.
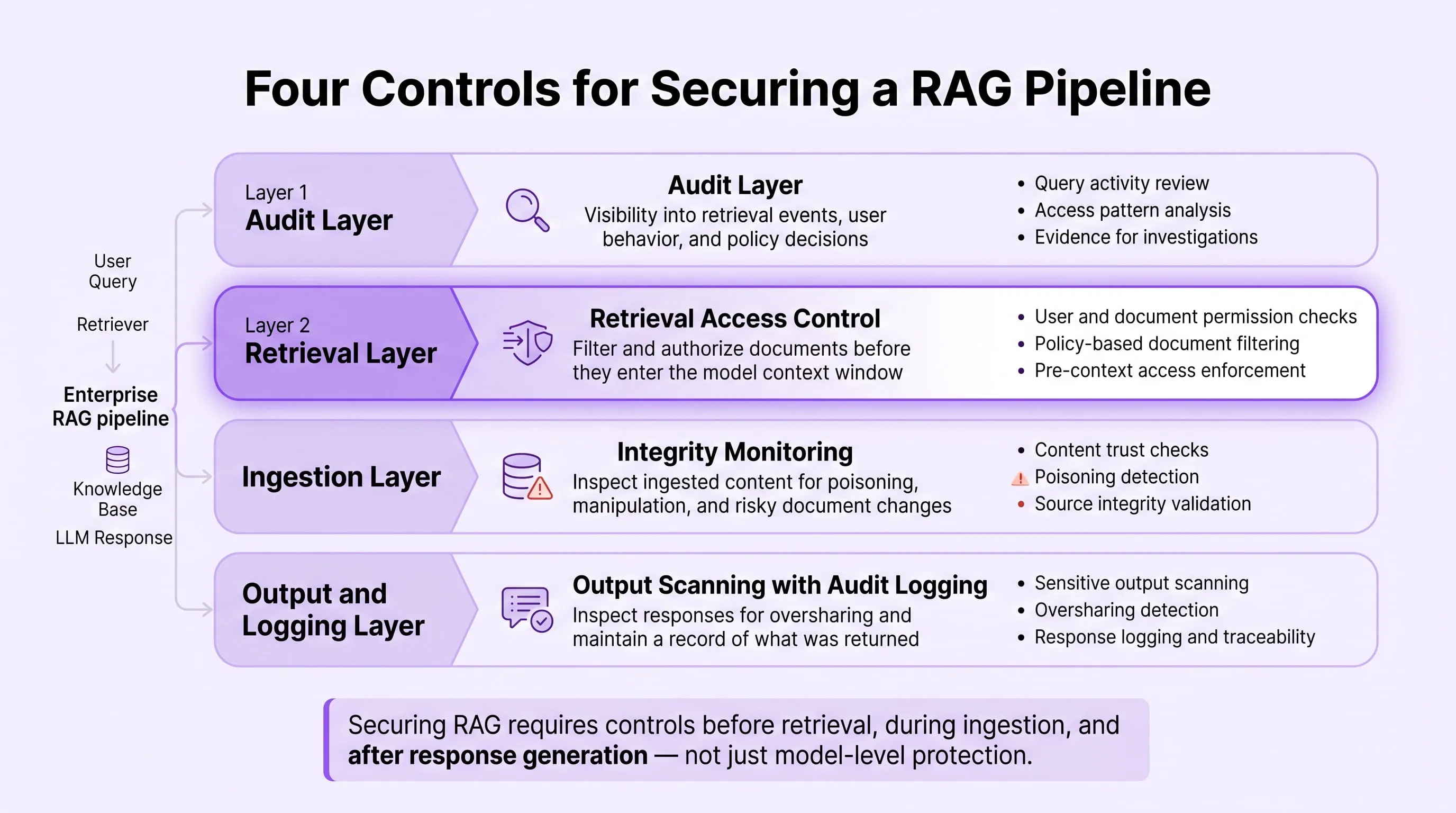
Control 1 - How Do You Know If Your RAG System Is Already Oversharing?
Run a chunk-level access audit and run it before implementing any other control. This is the only action in this framework that requires no procurement, no architectural change, and no additional tooling. It is also the control that tells you whether the problem already exists in your deployment.
A chunk-level access audit involves querying your RAG system with a set of test queries across different user permission levels and examining which document chunks each query returns.
In the majority of enterprise RAG assessments LangProtect has conducted, this single audit pass surfaces retrieval events in which confidential documents were returned to users whose access level did not cover those documents events that occurred weeks or months before the audit, with no log to show for them.
What a chunk-level access audit identifies:
- Which documents in your knowledge base are being retrieved by users who should not have access to them
- Whether your post-retrieval filter, if one exists is successfully removing unauthorised content before it reaches the model
- Whether your vector index contains document chunks from classification levels that should not share a retrieval pool
- The baseline state of your RAG access control architecture before any remediation is applied
Until you have run this audit, you do not know the extent of the oversharing exposure that currently exists in your deployment.
Control 2 - How Do You Stop the Retrieval Engine From Surfacing Unauthorised Documents?
Apply access-controlled retrieval at the vector layer before any document chunk enters the model's context window. This is the architectural control that closes the oversharing gap at its source.
Implementation requirements:
-
Separate vector stores by data classification level. Executive-level documents, confidential strategic content, and general-access materials must not share the same retrieval index. When they share an index, the retrieval engine has no mechanism to distinguish between them; it returns the highest-scoring chunks regardless of sensitivity level.
-
Apply permission-scope filtering at the retrieval step. Before any retrieved chunk is passed to the language model, the system must verify that the querying user has explicit access to the source document. This verification must occur at the retrieval layer; a permission check applied after retrieval has already run is too late. The document is already in the context window and the data is already in the model's response.
-
Do not rely on post-retrieval filters as a primary control. They are a secondary defence, not a substitute for retrieval-layer access control because they operate after the retrieval event has already occurred and the document has already been processed.
Control 3 - How Do You Prevent Attackers From Poisoning Your Knowledge Base?
Implement knowledge base integrity monitoring across every document source feeding the retrieval index. This is the control that closes the RAG poisoning gap because poisoning attacks succeed specifically when no mechanism exists to detect malicious content before it is ingested.
Implementation requirements:
-
Implement change detection on all document sources. Any new document ingested from an unexpected contributor, containing unusual formatting patterns, or including instruction-style language directed at the AI system should be flagged for review before ingestion into the knowledge base.
-
Apply hash-based integrity checking on ingested documents. Hashing detects tampering between the point of ingestion and the point of retrieval the specific window that RAG poisoning exploits. A document whose hash value changes between ingestion and retrieval has been modified after it entered the pipeline.
-
Restrict write access to knowledge base source documents using least-privilege principles. Not every employee who can query the RAG system should be able to add documents to the sources it ingests from. In most enterprise environments, SharePoint libraries, Confluence spaces, and Google Drive folders connected to RAG pipelines have write permissions that are far broader than the security team recognises.
-
Conduct quarterly write-access reviews across all document sources feeding the knowledge base. Access that was appropriate at the time of initial RAG deployment may no longer be appropriate as the system's scope has expanded.
Control 4 - How Do You Detect RAG Data Leakage That Has Already Occurred?
Apply output-direction scanning on every RAG response before it reaches the employee, and implement immutable audit logging at the retrieval pipeline level. These two capabilities work together: scanning catches leakage events in real time, and logging creates the forensic record that makes a suspected incident reconstructable after the fact.
Output scanning LangProtect Personal Data Protection (Output) scanner runs on every AI-generated response before it is displayed to the user. It detects sensitive data the model may have surfaced from the retrieval context whether through oversharing or through a poisoning-induced exfiltration and masks it before the response reaches the employee's screen.
This control catches leakage events that access-controlled retrieval did not prevent, including edge cases where a document entered the index before classification controls were in place.
Retrieval-layer audit logging every retrieval event must be logged at the pipeline level with the following fields:
- The original user query
- The documents retrieved in response, including document ID and classification level
- The specific chunks that entered the model's context window
- The AI-generated response
- Any enforcement action taken by output scanning
- The user identity, session ID, source application, and timestamp
This logging record is what EU AI Act Article 12 requires for high-risk AI deployments a complete audit trail of what the retrieval system surfaced, to which users, in response to which queries. It is also what transforms a suspected RAG data leakage incident from an unmanageable forensic exercise into a contained, evidenced response with a clear chain of events.
Standard application logs record an HTTPS request to an AI API endpoint. They do not capture which documents were retrieved, which chunks entered the context window, or what was generated in response. EU AI Act Article 12 compliance requires retrieval-layer instrumentation; not API-level telemetry. The full framework of what AI governance obligations require at the technical layer, including the specific logging standards that satisfy Article 12, is set out in LangProtect's analysis of what AI governance actually requires in 2026.
Frequently Asked Questions
Q: What is the difference between RAG oversharing and RAG poisoning?
A: RAG oversharing is an architectural failure, the retrieval engine surfaces documents a user was not authorised to see because access controls are applied at the application layer rather than the retrieval layer. RAG poisoning is an adversarial attack, a threat actor injects content into the knowledge base to manipulate AI responses or cause the system to exfiltrate other documents. Both produce data leakage but they exploit different vulnerabilities and require different controls to prevent.
Q: Why do standard access controls fail to prevent RAG data leakage?
A: Most enterprise access controls determine who can submit a query to the RAG system; they operate at the UI or API layer. The retrieval engine runs below this layer and searches the full vector index without any concept of user permissions. By the time an application-layer permission check fires, the document is already in the model's context window. The access control needs to operate at the retrieval step, before the document enters the model; not after.
Q: Can vector embeddings be used to reconstruct the original documents?
A: Yes, this is called an embedding inversion attack. Researchers at the University of Pisa demonstrated that a black-box attacker with query access to a RAG system can reconstruct the contents of private knowledge base documents through adaptive query generation, without direct access to the raw document store. A vector index is not an anonymised representation of your documents, it is a recoverable version of them that requires the same access controls as the source files.
Q: Does the EU AI Act apply to enterprise RAG systems?
A: It applies when the RAG system is used in a high-risk AI application category under Annex III; including HR decision support, credit scoring, healthcare diagnostics, education, and critical infrastructure. For high-risk deployments, Article 12 requires logging of all system inputs, retrieved documents, and generated outputs with an enforcement deadline of August 2, 2026. Penalties reach €35 million or 7% of global annual revenue.
Q: Can LangProtect secure our existing RAG deployment without requiring a full architecture rebuild?
A: Yes. LangProtect Armor adds access-controlled retrieval, knowledge base integrity monitoring, and output-direction scanning to existing RAG pipelines as a security layer; without requiring changes to the underlying vector store, embedding model, or retrieval infrastructure. The audit logging generated satisfies EU AI Act Article 12 and DORA Article 9 requirements by default.
Q: How quickly can LangProtect assess whether our RAG system has an oversharing or poisoning risk?
A: A LangProtect RAG security assessment takes 30 minutes and covers the four highest-risk areas: access control architecture at the retrieval layer, knowledge base integrity and write-access governance, output scanning coverage, and retrieval-layer audit log completeness. Book a session.