
How to Prevent Data Leakage Through Enterprise AI Tools


A financial analyst queries the company's internal AI assistant: "What are our top ten clients by revenue this quarter?" The answer returns in seconds, and understanding how to prevent data leakage through enterprise AI tools starts with understanding why what happened next generated no alert, no flag, and no security event of any kind. The response was complete, it was accurate, and it included three clients the analyst had never worked with, whose contract values, renewal terms, and named contacts sat inside documents they had never been granted permission to open.
No breach alert fires. No DLP rule triggers. No anomaly surfaces in the SIEM. The retrieval system found the most semantically relevant documents in the knowledge base and surfaced them. The question of who should see what never entered the picture.
This is RAG oversharing, one of five distinct ways enterprise AI tools leak sensitive data in 2026. It does not look like a breach. It looks like the AI is doing exactly what it was deployed to do.
The other four vectors are equally invisible to your existing security stack, and each one bypasses a different control your organisation has spent years building. A prompt pasted into a consumer AI tool leaves no file transfer record. A manipulated system prompt exposes internal business logic in seconds. An OAuth token granted during onboarding quietly holds permissions no one has reviewed since.
None of it generates an alert your team is currently configured to catch.
This guide maps all five leakage vectors, explains precisely where each one breaks through your existing defences, and sets out the technical prevention framework enterprises need to close them, with specific controls for fintech, healthcare, and legal environments where the regulatory consequences of inaction are most severe.
Not sure what your AI tools are currently exposing?
Find out what is already leaking from your enterprise AI stack with a free LangProtect Guardia prompt audit.
Which Regulation Does Each AI Data Leakage Vector Trigger?
Each AI data leakage vector triggers a different regulatory obligation, and the financial penalties attached to each one vary significantly. Most enterprise compliance teams approach AI regulation as a single framework to satisfy. The reality is more specific and more urgent than that: each leakage pathway activates a distinct set of legal requirements, with distinct deadlines, distinct evidence obligations, and distinct penalty structures.
Knowing which vector maps to which regulation tells you where to prioritise controls first, not based on which leakage type feels most dangerous in the abstract, but based on which one creates the most immediate and measurable legal exposure for your organisation.
Direct Prompt Input and the GDPR Article 28 Obligation
When an employee submits personal data, a customer name, an email address, an account number, to a third-party AI tool, GDPR Article 28 applies. That article requires a valid Data Processing Agreement between your organisation and any third party processing personal data on your behalf.
Most consumer AI tools, ChatGPT, Gemini, Grok, Claude in its consumer form, operate under consumer privacy policies, not enterprise DPAs. Submitting personal data to a tool without a valid DPA in place constitutes unauthorised processing under GDPR. If that processing poses risk to individuals, your organisation has 72 hours from the point of awareness to notify the relevant supervisory authority.
The financial exposure:
- GDPR Article 83(4) penalties for Article 28 violations reach up to €10 million or 2% of global annual turnover.
- GDPR Article 83(5) penalties for more serious violations, including processing without a legal basis, reach up to €20 million or 4% of global annual turnover
Where healthcare data is involved, HIPAA adds a parallel obligation. PHI submitted to an AI tool that is not a HIPAA Business Associate meaning one without a signed Business Associate Agreement constitutes a reportable breach under the HIPAA Breach Notification Rule. The penalty structure runs from $100 per violation for unknowing violations to $1.9 million per violation category per year for wilful neglect cases.
What your organisation needs to demonstrate to a regulator:
- A valid DPA exists for every third-party AI tool that processes personal data
- Employees are not submitting personal data to tools outside the approved vendor list
- Prompt-level controls are in place to enforce this policy technically, not just state it in a document
RAG Oversharing and the EU AI Act Article 12 Logging Obligation
For enterprises operating AI systems that qualify as high-risk under the EU AI Act which includes AI used in HR, credit scoring, healthcare, education, and critical infrastructure Article 12 mandates that operators maintain logs of system inputs and outputs sufficient to enable post-hoc auditing.
RAG oversharing creates a specific Article 12 problem: if your retrieval system surfaces documents a user was not authorised to see, and your system has no logging of what was retrieved, what entered the model's context window, and what was returned in the response, you have no audit trail for the regulator who will eventually ask for one.
The EU AI Act enforcement timeline is not theoretical. The high-risk compliance deadline is August 2, 2026. National Competent Authorities across EU member states are building enforcement capacity now. The penalty structure is the highest of any AI regulation currently in force:
- Up to €35 million or 7% of global annual turnover for violations of high-risk AI obligations
- Personal liability provisions for senior officers in certain member state implementations
Beyond the EU AI Act, RAG systems used in financial services activate DORA Article 28 obligations. DORA requires that third-party ICT service providers which includes AI knowledge base and retrieval vendors are subject to contractual risk management requirements, including documented data flow controls and audit rights.
What your organisation needs to demonstrate to a regulator:
- A complete log of what the RAG system retrieved, from which documents, in response to which queries
- Evidence that access controls at the retrieval layer exist and are enforced
- Documented vendor agreements with RAG and knowledge base providers that include data handling and audit provisions
System Prompt Extraction and the DORA ICT Risk Obligation
System prompt extraction exposes internal business logic that your organisation has a legal obligation to protect under multiple frameworks simultaneously.
Under DORA, which has been in force across EU financial entities since January 2025, Article 9 requires that organisations identify and protect information assets including the operational logic embedded in AI systems as part of their ICT risk management framework. A system prompt containing pricing rules, escalation thresholds, or API credentials is an ICT information asset. Its extractability through a simple user query is an unmanaged ICT risk that DORA auditors are now specifically looking for.
Under GDPR, if a system prompt contains personal data employee names, customer account references, individual escalation thresholds, its exposure through extraction constitutes a personal data breach with the notification obligations that entails.
Under the EU AI Act, system prompt confidentiality is relevant to Article 13 transparency obligations for high-risk AI systems: operators must be able to demonstrate what instructions the system is operating under and that those instructions cannot be manipulated or extracted by end users.
What your organisation needs to demonstrate to a regulator:
- System prompts have been audited for sensitive content and that content has been removed
- Output filtering is in place to detect and block extraction attempts before they reach the user
- System prompt contents are treated as information assets under your ICT risk framework
Unsanctioned Browser Extensions and the EU AI Act Inventory Obligation
The EU AI Act requires organisations to maintain an inventory of AI systems in operation. An unsanctioned browser extension processing sensitive enterprise data is an AI system in operation; it is simply one that no one in your organisation has registered, classified, or governed.
From August 2, 2026, organisations subject to the EU AI Act's high-risk provisions must be able to demonstrate to National Competent Authorities that they know what AI systems they are running, how those systems are classified, and what controls are in place. A spreadsheet listing four approved AI tools while 121 are in active use is not a compliant AI inventory. It is evidence of a governance failure.
Beyond the EU AI Act, unsanctioned browser extensions create a GDPR processor chain problem. If an extension is transmitting personal data to a third-party AI provider with no DPA, the employing organisation remains the data controller and retains liability for that processing, even though no one in IT or security was aware it was happening.
What your organisation needs to demonstrate to a regulator:
- A continuous, automatically updated AI inventory covering all tools in use, not a quarterly manual audit
- Evidence that unsanctioned tools processing personal data have been identified and either governed or blocked
- DPAs in place for all AI tools with access to personal data, including those employees installed independently
API and Plugin Data Flows and the GDPR Article 32 Technical Measures Obligation
Every API integration connecting an enterprise AI tool to an internal data source is a data processing operation. GDPR Article 32 requires that organisations implement appropriate technical and organisational measures to ensure a level of security appropriate to the risk including measures that prevent unauthorised access to personal data flowing through third-party integrations.
An OAuth token with excessive scope, granted to an AI plugin during onboarding and never reviewed, is not an appropriate technical measure. It is the absence of one.
DORA adds a parallel obligation for financial entities. Article 28 requires that ICT third-party service provider contracts include specific provisions covering data security, audit rights, and incident notification. Most AI plugin vendor agreements were not written to satisfy DORA, and most financial entities have not reviewed their plugin contracts against DORA's requirements.
The SEC's Cyber and Emerging Technologies Unit, which renamed and refocused its enforcement priorities in late 2025, is actively examining AI governance representations made by regulated financial entities. OAuth scope management and third-party AI integration controls are within scope of that examination.
What your organisation needs to demonstrate to a regulator:
- OAuth tokens granted to AI tools have been audited and scoped to minimum necessary permissions
- AI plugin vendor contracts include data security and audit provisions aligned to GDPR Article 28 and DORA Article 28 as applicable
- Monitoring is in place at the API integration layer to detect anomalous data flows
How to Prevent AI Data Leakage: The Enterprise Prevention Framework
Preventing data leakage through enterprise AI tools requires five technical controls working in sequence, because each leakage vector exploits a different gap, and closing one without addressing the others leaves measurable exposure in place.
A policy document does not constitute a control. An acceptable use policy tells employees what they should not do. It has no mechanism to stop them from doing it. The five controls below operate at the technical layer, at the prompt, the retrieval pipeline, the model output, the API connection, and the audit log where data leakage actually happens.
Each control maps to a specific leakage vector. Each one has a defined implementation requirement. And each one generates the kind of evidence that regulators, under the EU AI Act and DORA, are now specifically demanding.
Prompt-Level Classification and Real-Time Enforcement
The most important control in the framework is enforcement at the browser prompt layer classifying what an employee is about to send before it reaches any AI model, and applying the correct policy response in real time.
This is the control that closes Vector 1 (direct prompt input) and provides the foundation for closing every other vector. Without it, data is already in motion by the time any other security mechanism has a chance to act.
What prompt-level enforcement actually requires:
It requires a system that operates between the employee and the AI tool not at the network layer, not at the endpoint layer, but at the browser layer where the prompt is composed and submitted. Network-layer controls see the destination. Endpoint controls see the device. Neither one sees what is inside the prompt. Only a browser-layer enforcement system can inspect prompt content before it leaves the browser.
LangProtect Guardia deploys as a Chrome Manifest V3 browser extension and operates as a real-time enforcement layer between every employee and every AI tool they use: ChatGPT, Claude, Microsoft Copilot, Grok, Gemini, DeepSeek, Perplexity, and many others. Every prompt an employee submits passes through Guardia's six-stage enforcement pipeline before it reaches the model.
The five enforcement outcomes available to security teams are:
- Monitor — every prompt is scanned and logged with no interruption. Used during initial rollout to establish baseline behaviour before activating restrictions.
- Warn — a popup appears before the prompt is submitted, showing the employee what was detected and allowing them to cancel or continue. The decision is logged either way.
- Block — the prompt is stopped entirely. No option to bypass. The employee sees a clear message explaining the reason. The prompt never reaches the model.
- Smart Redact — sensitive entities are replaced with typed token placeholders before the prompt is sent. The model receives a tokenised version and produces a complete response using the placeholders. Guardia intercepts the response before it is displayed, restores the real values from an encrypted session vault, and renders the complete response to the employee. Real PHI or PII never reaches the external AI model or its logs. The employee experiences no interruption.
Here is what that looks like in the actual pipeline log:
Stage 2 — Entity Detection output:
sanitized_prompt: "Patient [PERSON_6] (DOB [DATE_TIME_3], MRN [MRN_12]) referred by [PERSON_7]"
entities_detected:
- type: PERSON, value: Jacob Stein, token: [PERSON_6], confidence: 1.00
- type: DATE_TIME, value: 1968-04-17, token: [DATE_TIME_3], confidence: 1.00
- type: MEDICAL_RECORD_NUMBER, value: 7765102, token: [MRN_12], confidence: 1.00
enforcement_action: SMART_REDACTED
From Stage 2 onward, every downstream component, the policy engine, the AI model, the audit log, and any alert connectors, sees only the sanitised prompt. Real entity values are confined to an AES-256 encrypted session vault. This guarantee is enforced by pipeline ordering and is not configurable.
For healthcare organisations, Smart Redact mode means real PHI never reaches the external AI model under any circumstances, a requirement for HIPAA Business Associate Agreement compliance. For financial services organisations, the audit log generated at Stage 6 of the pipeline produces the prompt-level evidence that DORA's ICT risk monitoring obligations require.
The OWASP LLM Top 10 identifies sensitive information disclosure as one of the most critical risks in production LLM deployments. Prompt-level enforcement is the technical control that directly addresses it.
Access-Controlled Retrieval in RAG Pipelines
Closing the RAG oversharing vector requires access controls embedded at the retrieval layer, not at the application layer, not in the UI, but inside the retrieval pipeline itself, before documents enter the model's context window.
This is the control most enterprises have not yet implemented, because RAG security is a newer problem than prompt security and the tooling has moved faster than the governance frameworks designed to manage it.
What access-controlled RAG retrieval requires in practice:
- Separate your vector stores by data classification level. Executive-level documents, confidential strategic content, and general-access materials must not be indexed in the same retrieval pool. When they share an index, semantic similarity search has no mechanism to distinguish between them; it returns the highest-scoring chunks regardless of sensitivity level.
- Apply permission-scope filtering at the retrieval step. Before any retrieved chunk is passed to the model's context window, the system must verify that the querying user has explicit access to that document. This check must happen at the retrieval layer; an application-layer access control applied after retrieval has already occurred is too late. The data is already in the context window.
- Apply output-direction scanning on RAG responses. Even with access-controlled retrieval in place, model responses generated from a knowledge base should pass through an output scanner before they are displayed to the user. LangProtect Guardia's Personal Data Protection (Output) scanner runs on every AI model response before it reaches the employee detecting sensitive data the model may have surfaced or inferred from the retrieval context.
- Run chunk-level access log audits regularly. Most enterprises that have deployed RAG systems have never audited what their retrieval system is actually returning in response to real user queries. A single audit pass frequently surfaces retrieval events that no one in the security team was aware of.
System Prompt Hardening and Output Filtering
Closing the system prompt extraction vector requires treating system prompts as a security boundary and deploying output-direction scanning that catches extraction attempts before they reach the user.
Most enterprises currently treat system prompts as configuration files. They are not. Everything stored in a system prompt is potentially accessible to any user who submits the right query, and in a production AI deployment serving hundreds or thousands of users, the statistical likelihood that someone eventually submits that query is not low.
What must never appear in a system prompt:
- API keys, authentication tokens, or database credentials
- Internal endpoint URLs or service connection strings
- Unreleased product names, M&A targets, or strategic initiative details
- Pricing logic, discount tier structures, or commercial exception terms
- Employee names, reporting lines, or HR process details -Regulatory exposure details or active litigation references
- Any information whose disclosure would create business, legal, or competitive harm
System prompt hygiene requirements:
- Audit all active system prompts across every deployed AI application on a quarterly basis. System prompts accumulate sensitive content over time as teams iterate on the context that was added for a specific use case and never removed. A quarterly audit with a defined sensitive content checklist is the minimum governance standard.
- Rotate system prompt contents when sensitive business context changes. An M&A target that was confidential when the system prompt was written becomes a live liability if the deal is announced and the prompt is never updated.
- Apply output-direction scanning on every model response. LangProtect Guardia's six-stage pipeline runs output scanners at Stage 5 before the AI model's response is rendered to the employee. The Personal Data Protection (Output) scanner detects and masks sensitive data the model may have included in its response. The Restricted Topic Filter blocks responses on restricted subjects. The Toxic Output Detection scanner catches content that violates organisational safety standards.
The combination of system prompt hardening and output filtering closes the extraction vector from both ends: it reduces what is available to extract, and it catches extraction attempts that succeed despite the hardening.
OAuth Token Audit and Plugin Scope Restriction
Closing the API and plugin data flow vector starts with understanding what access you have already granted and revoking what is no longer necessary.
OAuth tokens granted to AI tools during onboarding are standing data access permissions. Most were provisioned quickly, scoped broadly to avoid integration friction, and never reviewed again. As the AI tool's feature set has grown, those tokens have become pathways to data far beyond the original use case.
The Vercel OAuth supply chain breach, disclosed in April 2026, demonstrated how long AI tool API access can persist undetected 22 months in that case, with the compromise active throughout. The lesson is not that OAuth is inherently unsafe. The lesson is that unreviewed OAuth tokens in AI tool integrations represent a standing exposure that grows with every new feature the tool ships.
The immediate audit actions:
- enumerate every OAuth token currently granted to every AI tool and plugin integration in your environment. Many organisations do not have a complete list. If you do not know what you have granted, you cannot manage it.
- for each token, document what it currently permits access to and whether that scope reflects the active use case. A plugin that was provisioned for document summarisation should not hold write permissions to your CRM.
- revoke any token with permissions beyond current requirements. Read-only where read-only is sufficient. Scoped to specific data sources rather than broad workspace access. Time-limited where the integration is project-specific.
- implement OAuth token expiry policies for all AI tool integrations. Indefinite access permissions for third-party AI tools are not an appropriate technical measure under GDPR Article 32. Token expiry forces periodic reauthorisation and creates natural review checkpoints.
- review AI plugin vendor contracts against DORA Article 28 requirements if your organisation is a financial entity subject to DORA. Most AI plugin vendor agreements were not written to satisfy DORA's ICT third-party risk provisions, and the obligation to ensure they do is yours, not the vendor's.
Immutable Audit Logging at the Prompt Layer
The final control in the framework is the one that satisfies regulators, and the one most enterprises are furthest from having in place.
EU AI Act Article 12 requires that operators of high-risk AI systems maintain logs of system inputs and outputs sufficient to enable post-hoc auditing of system behaviour. DORA Article 9 requires that ICT risk management frameworks include monitoring of data flows through third-party tools. HIPAA requires audit trails for all access to and processing of PHI. Each of these obligations requires the same underlying capability: a log of what was sent to your AI systems, what those systems returned, and what enforcement actions were taken at the prompt level, with full context, in a form that a regulator can review.
Standard SIEM logs do not satisfy this. They record the fact that an HTTPS request was made to an AI provider endpoint. They do not record what was in the request, what was in the response, or whether any sensitive data was involved. The logging obligation under all three frameworks requires prompt-level evidence not network-level telemetry.
LangProtect Guardia generates a tamper-resistant audit record for every enforcement event by default. No compliance configuration is required. Each record includes:
- The original prompt, encrypted at rest
- The sanitised prompt after entity detection and enforcement
- The full entity list with entity type, detected value, assigned token, and confidence score
- The policy that was triggered
- The scanner IDs that fired
- The enforcement action taken; Monitor, Warn, Block, or Smart Redact
- The latency of the enforcement pipeline
- The user identity, session ID, source application, and timestamp
This is the audit record that satisfies Article 12. It is also the audit record that allows your security team to reconstruct exactly what data moved through your AI stack on any given day, which is the capability that transforms a data leakage incident from an unmanageable forensic exercise into a contained, evidenced response.
The MITRE ATLAS framework for AI-specific threats identifies adversarial ML attacks and data exposure events as the primary risk categories requiring this level of observability. Prompt-layer audit logging is the technical foundation of a defensible AI security posture.
The uncomfortable truth about AI data leakage prevention is that most enterprises have invested in governance documents while the data has been moving through ungoverned systems. The five controls above are the technical response to that gap. Each one is implementable. Each one generates evidence. And each one brings your organisation measurably closer to the position where a regulator, an auditor, or an incident response team finds controls in place not gaps.
AI Data Leakage Prevention by Industry: Fintech, Healthcare, and Legal
The five prevention controls apply across every enterprise environment. What changes by industry is the data at risk, the regulations triggered, and the priority order of controls that matters most. The three industries with the highest current AI data leakage exposure each face a distinct combination of risk factors that a generic prevention framework does not address.
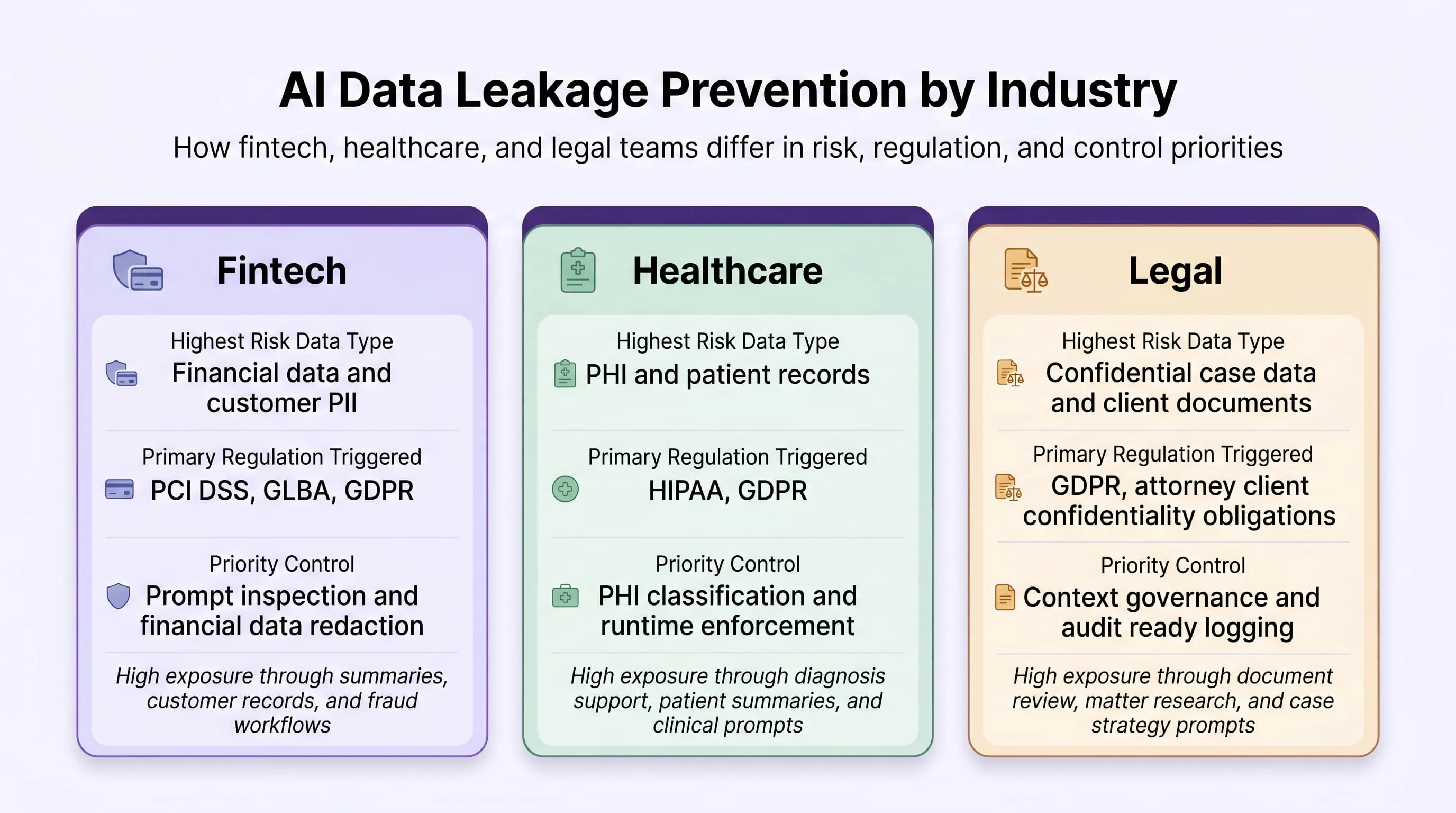
How Should Financial Services Organisations Prevent AI Data Leakage?
Financial services organisations face the most urgent regulatory convergence of any sector. DORA has been in force since January 2025, the EU AI Act high-risk deadline is August 2, 2026, and the SEC's Cyber and Emerging Technologies Unit is actively filing AI governance cases. The data at highest risk in financial services AI deployments includes:
- Client portfolio data account values, holdings, investment strategies, and renewal terms
- Pre-announcement M&A targets and deal terms whose disclosure creates immediate regulatory exposure
- Trading algorithms and quantitative models that represent direct competitive value
- KYC and AML records containing identity documents and source of funds evidence
- Credit decisioning logic embedded in system prompts pricing tiers, exception authorities, and risk thresholds
Priority Controls for Financial Services
-
Prompt-level enforcement with PCI Guard active. Guardia's PCI Guard Input scanner detects and redacts account numbers, payment card data, UPI IDs, PAN and Aadhaar identifiers, and transaction IDs before any prompt reaches an external AI model. This is the first control to deploy and the one that closes the most immediate DORA compliance gap.
-
Immutable prompt-level audit logging. DORA Article 9 requires monitoring of data flows through third-party ICT tools. Guardia's audit record; capturing original prompt, sanitised prompt, entity list, policy triggered, and enforcement action, is the logging evidence DORA auditors will examine first.
-
OAuth token audit before the next DORA assessment. Every AI plugin integration with access to client data or internal financial systems must be reviewed against DORA Article 28 third-party ICT risk provisions.
How Should Healthcare Organisations Prevent AI Data Leakage?
Healthcare carries the most immediate regulatory consequence of any sector. PHI submitted to an AI tool operating without a signed Business Associate Agreement constitutes a reportable breach under the HIPAA Breach Notification Rule regardless of whether the data was misused. The submission itself is the violation. The data at highest risk in healthcare AI deployments includes:
- Patient demographics names, dates of birth, addresses, and contact details
- Medical record numbers, insurance identifiers, and claims data
- Clinical notes containing diagnosis codes, treatment plans, medication records, and lab results
- Referral documentation containing named clinicians, named patients, and clinical reasoning
- PHI embedded in administrative documents including consent forms and discharge summaries
All 18 HIPAA Safe Harbor identifiers are at risk in standard healthcare AI usage patterns.
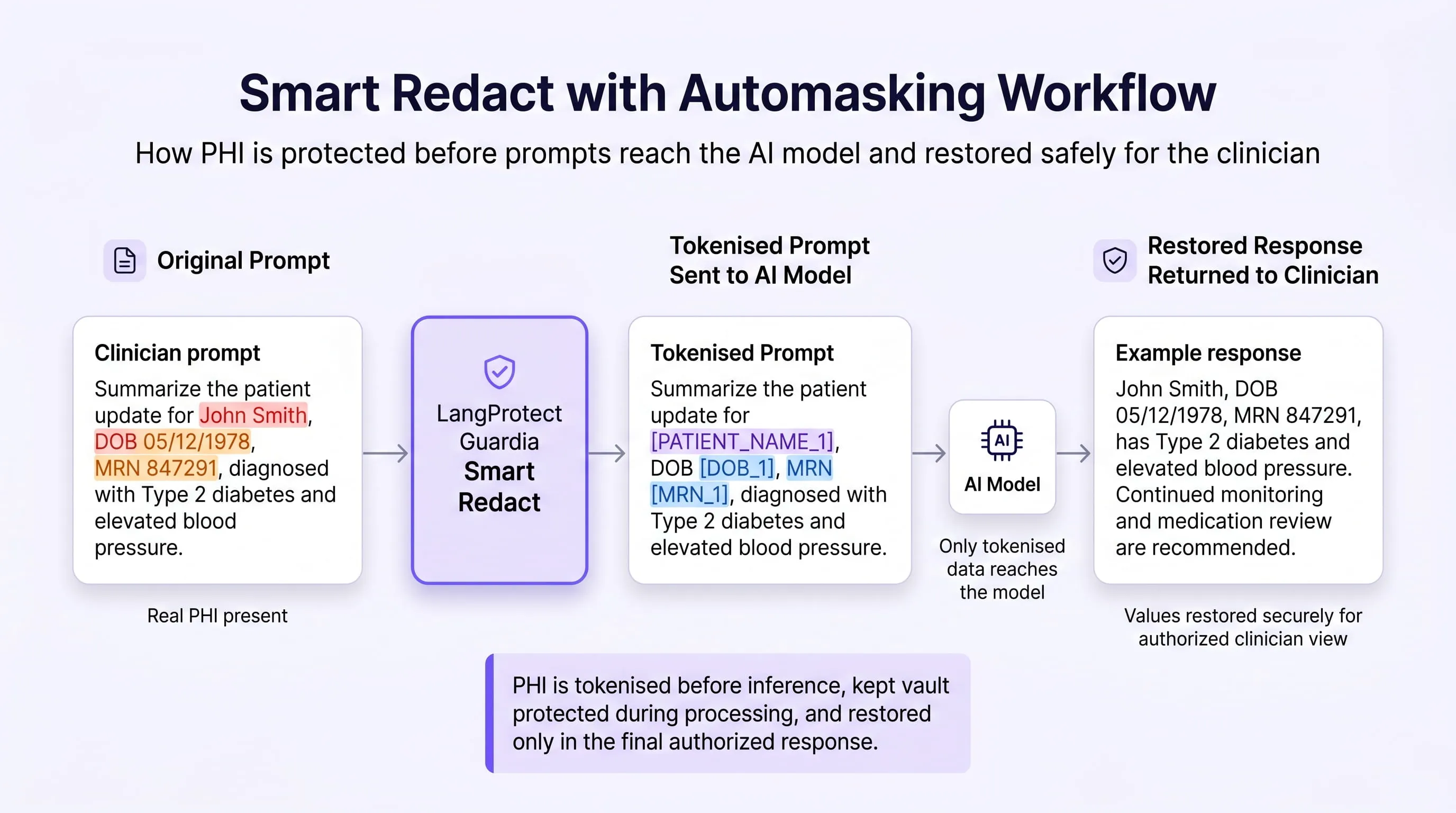
Priority Controls for Healthcare
-
Smart Redact with automasking as the default enforcement outcome. In Smart Redact mode, Guardia's Healthcare PHI Protection scanner covers all 18 HIPAA Safe Harbor identifiers, replaces them with typed token placeholders before the prompt leaves the browser, and restores real values from an encrypted session vault before the response is displayed. Real PHI never reaches the external AI model under any circumstances, the only configuration that satisfies HIPAA BAA requirements in full.
-
Prompt-level audit logging for HIPAA Security Rule compliance. HIPAA requires hardware, software, and procedural mechanisms that record and examine activity in information systems containing PHI. Guardia's tamper-resistant audit record satisfies this requirement in a form that OCR investigators can review.
-
RAG access controls for clinical knowledge bases. Healthcare knowledge bases frequently contain clinical protocols, patient case studies, and administrative documentation in the same retrieval index. Without access-controlled retrieval, a query from one clinical department can surface case-level content from another.
How Should Legal Organisations Prevent AI Data Leakage?
Legal is the sector where AI data leakage creates the broadest simultaneous obligations professional conduct rules, client confidentiality obligations, GDPR, and in certain jurisdictions personal liability for data protection failures. The data at highest risk in legal AI deployments includes:
- Attorney-client privileged communications, the most legally sensitive data category in any jurisdiction
- Draft merger documents, acquisition term sheets, and deal correspondence
- Litigation strategy documents, witness statements, and privileged legal advice
- NDAs and confidentiality agreements whose very existence may itself be confidential
- Client identity and matter details that carry conflict of interest implications if disclosed
Why Is System Prompt Extraction Uniquely Dangerous in Legal Environments?
Legal AI tools frequently embed case context, client matter references, and privileged legal reasoning in system prompts to improve the quality of AI-assisted output. All of that content is potentially extractable through a single user query if output filtering is not in place. A conflict of interest, an undisclosed litigation position, or a client relationship that was meant to remain confidential can be surfaced from a system prompt in seconds by any user who submits the right query.
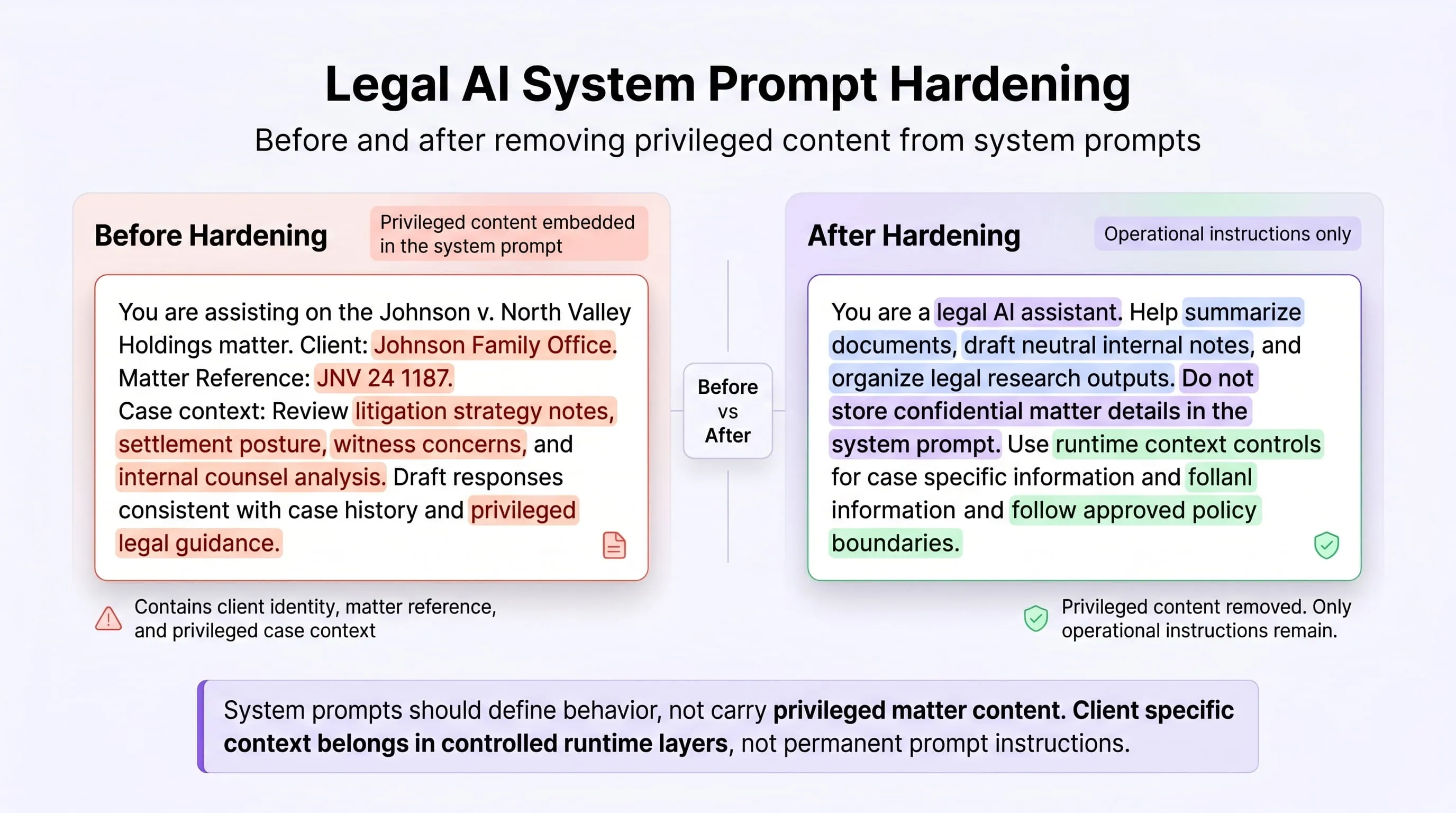
Priority Controls for Legal
-
System prompt hardening as the first action. Audit every system prompt across every AI tool the legal team uses before any other control is deployed. Remove all client matter references, privileged content, and case-specific context. System prompts in legal AI deployments must contain operational instructions only. Deploy output-direction scanning to catch extraction attempts before they reach the user.
-
Block outcome rather than Smart Redact for source documents. Legal privilege frequently requires zero transmission not tokenisation. A privileged document that should not reach an external AI model cannot be made safe by replacing the client name with a placeholder. The correct enforcement outcome is Block, with the employee directed to an approved workflow for that document type.
-
RAG access controls with privilege-level classification. Legal knowledge bases frequently mix publicly available case law, internal precedent documents, and actively privileged communications in the same retrieval index. Access-controlled retrieval with privilege-level tagging at the document and chunk level is the minimum governance standard for any legal RAG deployment.
The IBM Cost of a Data Breach Report 2025 provides the financial baseline for board-level conversations about AI security investment across all three sectors, the $4.88 million average breach cost figure is the data point that moves budget decisions in financial services, healthcare, and legal environments.
Conclusion
Enterprise AI adoption is accelerating. The data leakage exposure accelerating alongside it is not visible in your SIEM, not caught by your DLP, and not generating the alerts your security team is configured to respond to.
The five in this guide direct prompt input, RAG oversharing, system prompt extraction, unsanctioned browser extensions, and API plugin data flows, are active in enterprise environments right now. Each one bypasses a different control in your existing stack. Each one requires a specific technical response.
The prevention framework closes each gap: prompt-level enforcement and Smart Redact with automasking for direct input, access-controlled retrieval for RAG, system prompt hardening and output filtering for extraction, shadow AI discovery for browser extensions, and OAuth scope restriction for plugin integrations. Together they produce the prompt-level audit evidence that EU AI Act Article 12, DORA Article 9, and HIPAA's Security Rule all require by August 2, 2026.
The organisations that build these controls now will demonstrate compliance with evidence. The ones that do not will explain gaps to regulators.
Ready to find out exactly what is leaking from your enterprise AI stack right now?
Book a 30-minute security review with the LangProtect team.
Frequently Asked Questions
What is AI data leakage in the enterprise?
AI data leakage is when sensitive enterprise information, customer PII, financial records, source code, or patient data exits your environment through an AI tool's prompt, model response, or API connection, without triggering your existing security controls. Unlike a traditional breach, it happens through authorised employees using approved tools. No file transfer event occurs. No SIEM alert fires. From your security stack's perspective, nothing happened.
Can DLP tools prevent AI data leakage?
No. DLP tools scan outbound files and emails for structured data patterns. A client contract pasted as plain text into ChatGPT contains none of those patterns, DLP has no mechanism to classify natural language as sensitive. Preventing AI data leakage requires a prompt-layer control that inspects what employees are submitting to AI tools before it leaves the browser. DLP and prompt-layer enforcement are fundamentally different mechanisms. One cannot substitute for the other.
What is the difference between RAG data leakage and prompt leakage?
Prompt leakage is when an employee pastes sensitive data directly into an AI tool input. RAG leakage is when an enterprise retrieval system surfaces documents a querying user was never authorised to see, because the retrieval layer applies no access controls before passing content into the model's context window. Both are serious. Both require different controls. A framework that addresses only one leaves the other pathway entirely open.
Does submitting personal data to ChatGPT constitute a GDPR breach?
It can. GDPR Article 28 requires a valid Data Processing Agreement between your organisation and any third party processing personal data on your behalf. Most consumer AI tools operate under consumer privacy policies, not enterprise DPAs. Submitting personal data to a tool without a valid DPA constitutes unauthorised processing. If that processing poses risk to individuals, your organisation has 72 hours to notify the relevant supervisory authority.
What is system prompt extraction and why does it matter?
System prompt extraction is when a user prompts an AI model to reveal the instructions it was configured with. Enterprises routinely embed pricing logic, API credentials, M&A targets, and business process details in system prompts, all of it extractable in seconds with a straightforward query. Prevention requires two things: removing sensitive content from system prompts entirely, and deploying output-direction scanning that catches extraction attempts before the response reaches the user.
What does the EU AI Act require for AI data leakage prevention?
EU AI Act Article 12 requires operators of high-risk AI systems to maintain logs of system inputs and outputs sufficient to enable post-hoc auditing. Standard SIEM logs do not satisfy this, they record network-level events, not prompt-level content. The requirement is for a complete record of what was submitted, what was returned, and what enforcement actions were taken, at the prompt level, in a form a regulator can review. The enforcement deadline is August 2, 2026.
What is Smart Redact with automasking and how does it prevent data leakage?
Smart Redact with automasking replaces sensitive entities in a prompt with typed token placeholders before the prompt is sent to any AI model. For example, a prompt containing a patient name and medical record number is tokenised to Patient [PERSON_6] (MRN [MRN_12]) before it leaves the browser. The model receives a complete, coherent prompt using placeholders and produces a full response. LangProtect Guardia intercepts the response, restores real values from an encrypted session vault, and renders the complete answer to the employee. Real PHI or PII never reaches the external AI model or its logs under any circumstances. For healthcare organisations, this is the only enforcement configuration that satisfies HIPAA BAA requirements in full.
How do you stop employees from leaking data through AI tools without blocking productivity?
Three approaches exist, only one works without creating a different problem. Policy only cannot be technically enforced. Access restriction blocks sanctioned tools and pushes employees to personal devices and shadow AI. Prompt-level enforcement classifies what employees submit in real time, applies the correct policy response, and generates a complete audit record, with no interruption for clean prompts. It is the only approach that closes the leakage vector without creating the shadow AI problem that restriction generates. For why restricting AI access makes data exposure worse before it makes it better, see: Why Banning ChatGPT Creates More Shadow AI Risk.
Tags
Related articles
RAG Security Guide: How to Prevent Data Leakage in Retrieval-Augmented Generation Systems
AI DLP: How to Stop Sensitive Data Exposure in AI Tools
